En este post comparto el README del proyecto “Predicción mensual de nuevas maternidades en una organización”, en el que se desarrolla un modelo de regresión lineal múltiple para estimar el volumen mensual esperado de nuevas bajas maternales equivalentes de trabajadoras.
Puedes acceder al repositorio completo aquí: [enlace a GitHub]
A continuación resumo el contenido del proyecto y explico el recorrido seguido: desde la construcción del dataset hasta la comparación del modelo contra reglas simples de predicción y su despliegue en una pequeña aplicación con Streamlit.
Este repositorio desarrolla un proyecto completo de predicción cuantitativa aplicada a la gestión de recursos humanos hospitalarios. El objetivo es construir, evaluar y desplegar un modelo capaz de estimar el volumen mensual esperado de nuevas maternidades equivalentes. No se trata de predecir decisiones individuales, sino de anticipar un fenómeno agregado que puede afectar a la planificación de sustituciones, la organización asistencial y la previsión presupuestaria.
La idea del proyecto no es presentar un sistema productivo cerrado, sino mostrar un recorrido reproducible: cómo se define una pregunta de predicción, cómo se construye una variable objetivo, cómo se preparan los datos, cómo se comparan modelos y cómo se evalúa si el resultado mejora reglas simples de predicción.
1. Empezar por una pregunta de predicción
Todo proyecto predictivo debería empezar con una pregunta concreta. En este caso, la pregunta es: ¿podemos anticipar el volumen mensual de nuevas bajas maternales equivalentes de trabajadoras en un hospital utilizando información agregada de plantilla, estabilidad contractual, estructura familiar aproximada y riesgo durante el embarazo?
La predicción se plantea a escala mensual porque esta frecuencia es especialmente útil para la planificación operativa. En gestión de personal, muchas decisiones relevantes se toman mes a mes: previsión de sustituciones, necesidades de cobertura, tensión organizativa y estimación de gasto.
La clave está en transformar una preocupación organizativa en una variable modelable. No basta con decir “queremos prever maternidades”. Primero hay que decidir qué significa exactamente esa previsión y cómo se medirá.
2. Definir bien la variable objetivo
La variable objetivo del proyecto es:
mat_eq_nuevas_mes
Esta variable representa las nuevas maternidades equivalentes mensuales. Se calcula dividiendo los días de nuevas maternidades generados dentro del mes entre los días naturales del mes.
La idea es sencilla. Una baja maternal que empieza el día 1 genera una carga equivalente mayor en ese mes que una baja que empieza el día 28. Por eso, un simple recuento de maternidades nuevas puede ser insuficiente. Dos meses con el mismo número de nuevas bajas pueden tener un impacto mensual muy diferente si las fechas de inicio no son las mismas.
Por ejemplo, si una baja maternal empieza el día 16 de un mes de 30 días, aporta 15 días dentro de ese mes. Su valor equivalente será:
15 / 30 = 0,5
Esta decisión muestra una de las ideas centrales del proyecto: antes de elegir un modelo, hay que definir bien la magnitud que queremos predecir.
3. Construir un dataset con variables que puedan aportar señal
El dataset trabaja con información mensual agregada. Entre las variables explicativas se incluyen la plantilla equivalente de mujeres de 25 a 40 años, el porcentaje de trabajadoras indefinidas, una proxy administrativa de estructura familiar y varios indicadores retardados de riesgo durante el embarazo.
La variable de riesgo durante el embarazo es especialmente interesante porque puede funcionar como una señal adelantada. Algunas situaciones de riesgo durante el embarazo terminan posteriormente en una baja maternal, por lo que tiene sentido probar si los valores de meses anteriores ayudan a anticipar nuevas maternidades equivalentes.
Por eso se incluyen variables como:
RE_ponderado_lag1
RE_ponderado_lag2
RE_ponderado_lag3
También se incorporan retardos de la propia variable objetivo, como mat_eq_lag1 y mat_eq_lag12, para capturar inercia reciente o posibles patrones anuales.
Los datos publicados son ficticios y se utilizan con finalidad educativa. Esto permite compartir el flujo completo del proyecto sin exponer información sensible ni datos administrativos reales.
4. Mirar los datos antes de modelar
El primer notebook del proyecto, 01_data_cleaning_eda.ipynb, está dedicado a la limpieza, transformación y análisis exploratorio de los datos.
En esta fase se revisan tipos de datos, valores nulos, formato de fechas, orden temporal y estadísticas descriptivas. También se visualiza la evolución de la variable objetivo y se compara con variables como ppef_mujeres_25_40 y RE_ponderado.
El objetivo de esta fase no es encontrar todavía “el mejor modelo”, sino comprobar si el problema tiene sentido desde el punto de vista de los datos. Es decir, si la variable objetivo presenta variabilidad suficiente, si las variables explicativas se comportan de forma coherente y si existen relaciones plausibles que justifiquen avanzar hacia una regresión lineal múltiple.
También se analizan correlaciones de Pearson y Spearman, así como la colinealidad entre predictores mediante matriz de correlación y VIF. Esto es importante porque, en una regresión lineal múltiple, no basta con que las variables estén relacionadas con la variable objetivo: también hay que vigilar que no sean excesivamente redundantes entre sí.
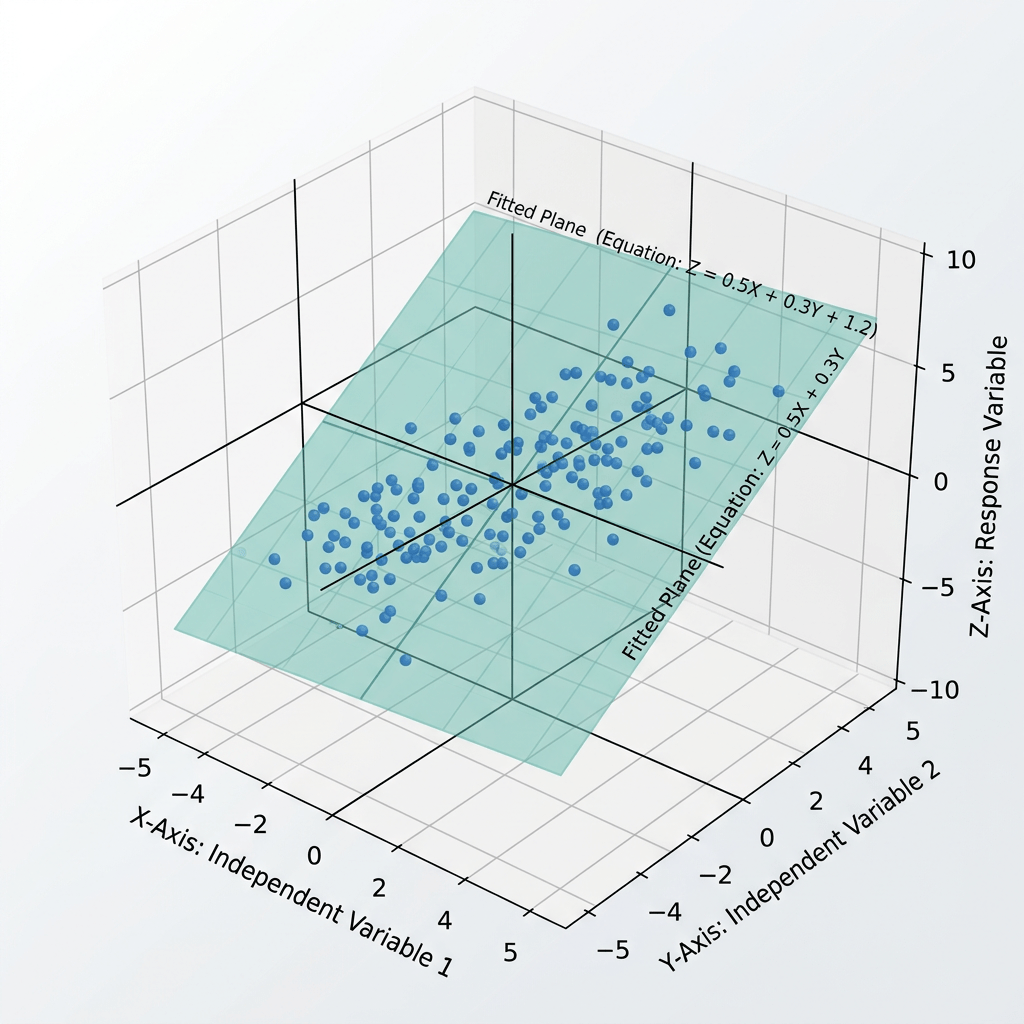
5. Construir modelos de regresión lineal múltiple
El segundo notebook, 02_modeling.ipynb, construye y compara modelos de regresión lineal múltiple. A diferencia de una regresión lineal simple, aquí no hay una única variable explicativa. El objetivo es combinar varias señales: plantilla, estabilidad contractual, estructura familiar aproximada, riesgo durante el embarazo, retardos temporales y estacionalidad mensual.
El notebook compara dos enfoques:
scikit-learn LinearRegression
statsmodels OLS
El primero es especialmente útil para predicción y despliegue. El segundo es más rico para interpretar coeficientes y revisar el modelo desde una perspectiva estadística.
Un punto importante es que no se prueban combinaciones de variables sin criterio. El proyecto genera combinaciones de forma controlada, limita el tamaño de los modelos y evita combinaciones redundantes, como incluir varios retardos muy parecidos del mismo indicador.
La evaluación se realiza con una división temporal train/test. Esto es importante porque se trabaja con una serie mensual: no tendría sentido mezclar meses aleatoriamente. En un contexto real, el modelo se entrena con el pasado y se utiliza para anticipar meses futuros.
6. Comparar el modelo contra baselines
El tercer notebook, 03_baselines_and_model_comparison.ipynb, responde a una pregunta fundamental:
¿El modelo de regresión lineal múltiple mejora realmente reglas simples de predicción?
Esta parte me parece especialmente importante. Un modelo sólo tiene sentido si mejora alternativas sencillas, transparentes y fáciles de implementar. Por eso se compara el mejor modelo de regresión lineal múltiple contra varios baselines: media histórica global, media histórica por mes, último valor observado, mismo mes del año anterior y media móvil de tres meses.
La métrica principal es el MAE —Mean Absolute Error— porque se interpreta en las mismas unidades que la variable objetivo. Un MAE de 1,2 significa que el modelo se equivoca, de media, en unas 1,2 maternidades equivalentes mensuales.
La selección del modelo no depende sólo del menor error. También se tienen en cuenta la parsimonia, la interpretabilidad, la estabilidad, la colinealidad y la mejora frente a baselines.
Esta comparación ayuda a evitar una trampa habitual: confundir complejidad con utilidad. Si una regla simple predice igual o mejor que el modelo, quizá la regla simple sea suficiente. Si el modelo mejora claramente los baselines, entonces empieza a tener sentido como herramienta de apoyo.
7. Llevar el modelo a una aplicación interactiva
El proyecto también incluye una aplicación desarrollada con Streamlit, ubicada en:
app/app.py
La app permite cargar el dataset de modelado, visualizar la serie histórica, consultar métricas descriptivas, ver un gráfico de correlaciones, comparar el modelo contra baselines, introducir escenarios manuales y obtener una predicción mensual esperada.
La versión desplegable utiliza un pipeline basado en:
StandardScaler + LinearRegression
y permite simular escenarios introduciendo valores para:
ppef_mujeres_25_40
RE_ponderado_lag1
mes
Esta parte del proyecto es útil porque muestra cómo un modelo puede salir del notebook y convertirse en una pequeña herramienta de simulación. No es un sistema productivo completo, pero sí una forma clara de enseñar cómo una predicción puede transformarse en una interfaz interactiva.
8. Qué se aprende con este proyecto
El proyecto no busca eliminar la incertidumbre. Busca reducirla de forma medible. Un modelo se considera útil si mejora claramente los baselines simples, mantiene un error medio aceptable, utiliza pocas variables, produce resultados interpretables y puede integrarse en una herramienta de apoyo a la planificación.
También muestra algunas limitaciones importantes. Se trabaja con datos agregados mensuales, no se predicen decisiones individuales, algunas variables son proxies imperfectas y la relación entre riesgo durante el embarazo y maternidad puede cambiar con el tiempo. Por eso el modelo debería revisarse y reentrenarse periódicamente.
Entre las posibles mejoras futuras están la validación rolling-origin, la comparación con Ridge y Lasso, la construcción de intervalos de predicción, la mejora del indicador RE_ponderado y el modelado del arrastre de maternidades activas.
Reflexión final
Este proyecto muestra cómo una técnica sencilla e interpretable como la regresión lineal múltiple puede aplicarse a un problema realista de gestión hospitalaria. La predicción mensual de nuevas maternidades equivalentes no elimina la incertidumbre, pero ayuda a pensarla de forma más estructurada. Convierte información administrativa dispersa en una estimación útil para planificar, comparar escenarios y tomar mejores decisiones.
Lo más importante no es sólo el modelo final. Es el recorrido completo: definir bien la variable objetivo, construir el dataset, explorar relaciones, comparar modelos, medir el error y contrastar siempre el resultado contra baselines simples.
En predicción cuantitativa, el objetivo no es adivinar el futuro. Es reducir la incertidumbre con método. Y a veces, una regresión lineal múltiple bien formulada puede ser una primera herramienta suficiente para empezar a hacerlo.