Naked Statistics: Stripping the Dread from the Data, publicado en 2013 por Charles Wheelan, parte de una idea sencilla: para comprender la estadística no es imprescindible comenzar por las fórmulas. Antes de calcular medias, probabilidades o regresiones, conviene entender qué preguntas intentan responder estas herramientas.
El propósito del libro no es formar estadísticos, sino reducir el temor que suele provocar la estadística. Wheelan recurre a historias y ejemplos relacionados con la economía, la medicina, las encuestas, los seguros o el deporte para mostrar cómo los datos intervienen constantemente en nuestras decisiones.
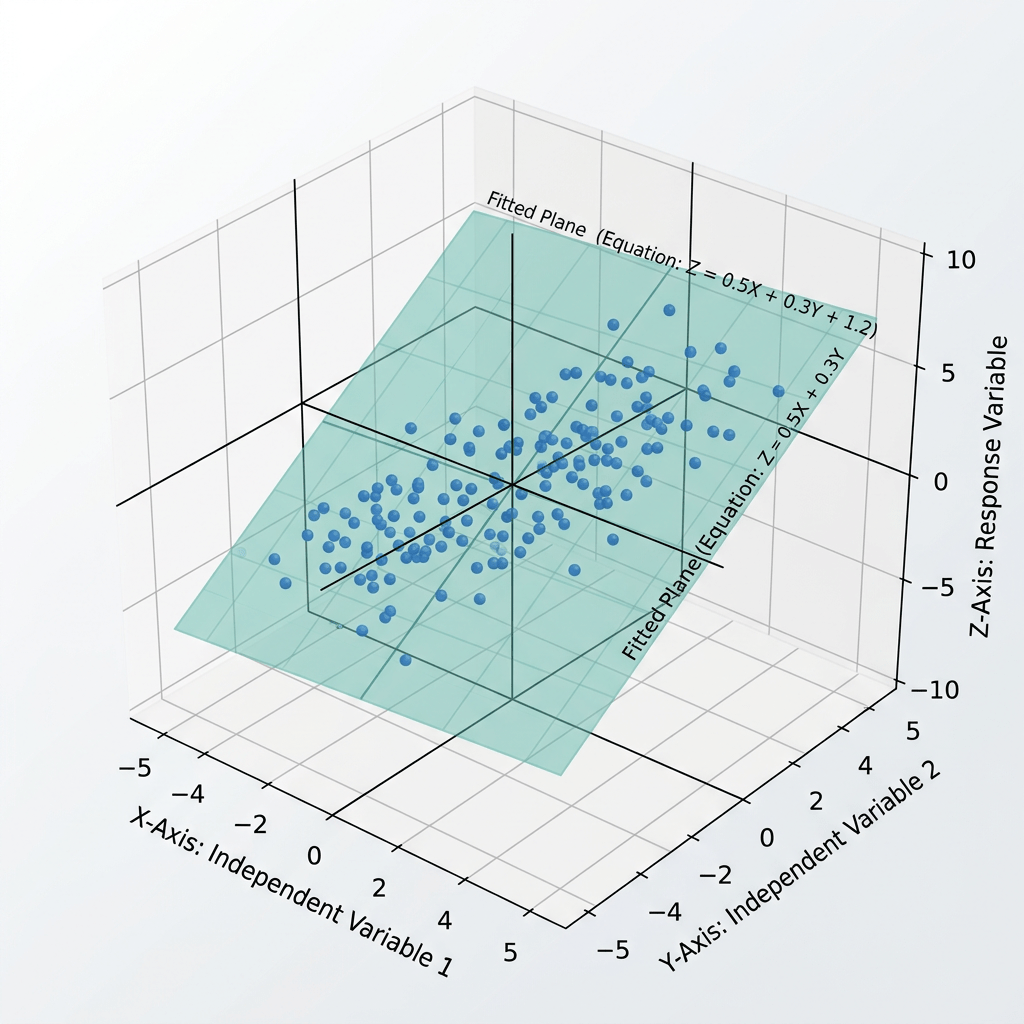
A lo largo de trece capítulos, el libro avanza desde la estadística descriptiva hasta la probabilidad, el muestreo, la inferencia, la regresión y la causalidad. Su argumento central es que una cifra puede ser matemáticamente correcta y, aun así, ofrecer una representación engañosa de la realidad.
Seguir leyendo «Reseña del libro «Naked Statistics: Stripping the Dread from the Data»»