En muchos fenómenos reales, una sola variable no basta para explicar lo que ocurre. El precio de una vivienda no depende únicamente de sus metros cuadrados, sino también de su ubicación, su antigüedad o su estado de conservación. El rendimiento académico no se relaciona sólo con las horas de estudio, sino también con el descanso, el contexto familiar o la dificultad de la materia.
La pregunta que aparece entonces es una extensión natural de la que ya planteaba la regresión lineal simple: si una variable puede ayudarnos a predecir otra, ¿qué ocurre cuando intervienen varias al mismo tiempo?
Uno de los modelos más importantes para abordar esta situación es la regresión lineal múltiple. Su idea central sigue siendo sencilla, pero su alcance es mucho mayor: permite estimar cómo se relaciona una variable con varias explicaciones simultáneas y construir predicciones más ricas y realistas.
Una idea un poco más ambiciosa
La regresión lineal múltiple intenta responder a una pregunta concreta: cómo cambia una variable cuando cambian otras varias a la vez.
La lógica de partida es similar a la de la regresión lineal simple. Seguimos teniendo una variable objetivo, que es aquello que queremos explicar o predecir, pero ahora ya no contamos con una sola variable explicativa, sino con varias. Cada una aporta una pieza parcial de información sobre el fenómeno que estamos observando.
El modelo mantiene una hipótesis útil: aunque la realidad sea compleja, podemos aproximar el efecto combinado de esas variables mediante una relación lineal. No se trata de decir que el mundo sea simple, sino de construir una primera representación ordenada de esa complejidad.
La intuición detrás del modelo
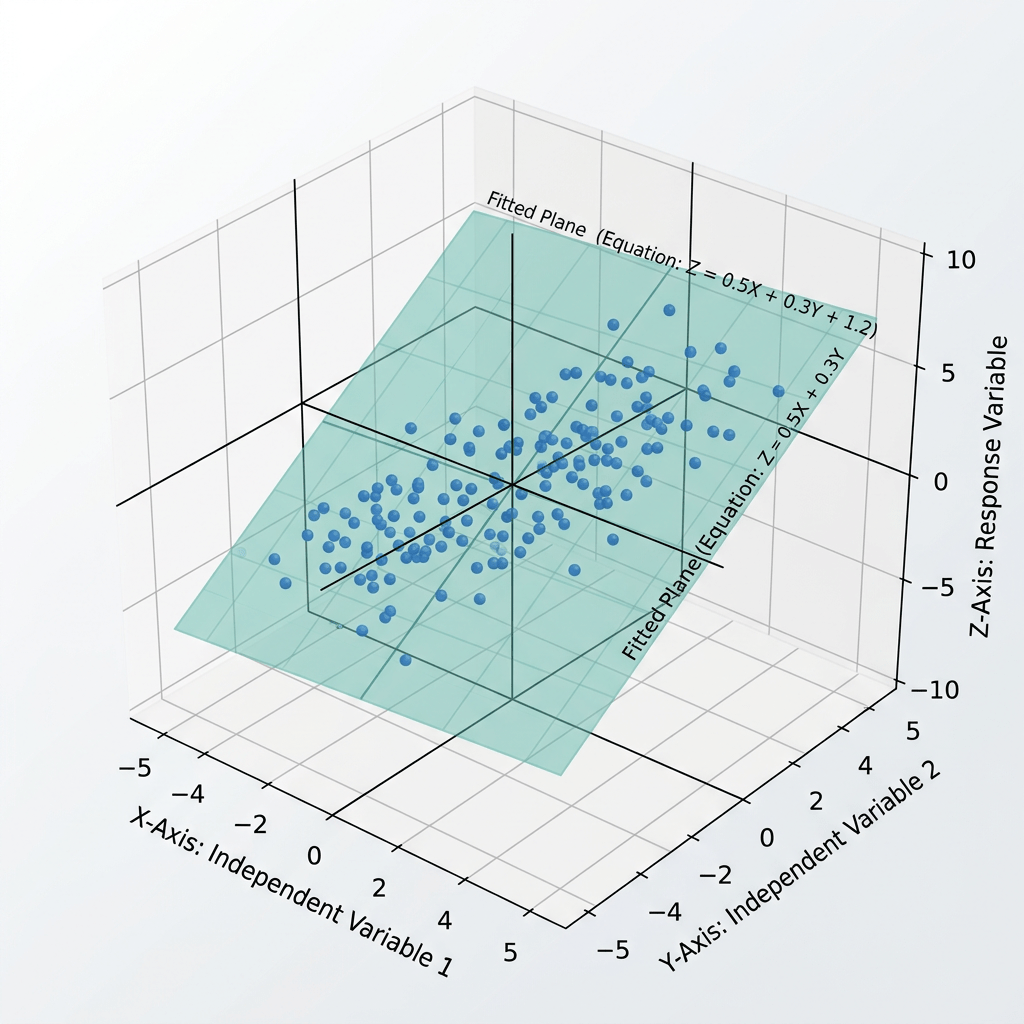
Cuando sólo teníamos una variable explicativa, podíamos imaginar una nube de puntos y una recta que resumía su tendencia. En la regresión lineal múltiple esa imagen deja de ser suficiente, porque ya no trabajamos en un plano, sino en un espacio con más dimensiones.
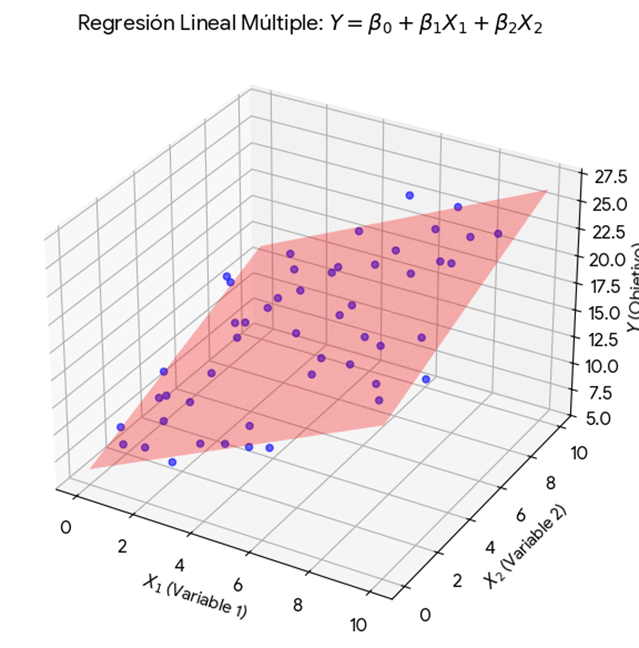
Eso puede sonar abstracto, pero la intuición sigue siendo la misma. El modelo busca la superficie que mejor se ajusta a los datos cuando intervienen varios factores al mismo tiempo. En lugar de resumir una relación entre dos variables, intenta capturar un equilibrio entre muchas influencias parciales.
Lo importante es que esta formulación permite algo muy valioso: estimar el efecto de cada variable manteniendo constantes las demás. Es decir, no sólo observamos que dos cosas se mueven juntas, sino que tratamos de aislar cuánto aporta cada factor por separado dentro de un sistema más amplio.
La forma matemática
Formalmente, la regresión lineal múltiple se expresa así:
- El término β₀ representa el intercepto: el valor esperado de Y cuando todas las variables explicativas valen cero.
- Los coeficientes β₁, β₂, …, βk indican cuánto cambia Y cuando aumenta una unidad la variable correspondiente, suponiendo que el resto permanece constante. Esa última precisión es esencial, porque en este modelo cada efecto debe interpretarse en presencia de los demás.
- El término ε recoge, una vez más, todo aquello que el modelo no logra explicar. Incluso cuando incorporamos muchas variables, siempre queda una parte de la realidad fuera de nuestra representación: factores omitidos, errores de medición, azar o simplemente una complejidad que no cabe en una ecuación lineal.
De una sola causa a una explicación más completa
La principal ventaja de la regresión lineal múltiple es que se acerca mejor a cómo suelen funcionar los fenómenos reales. Rara vez una sola causa basta para explicar un resultado. Lo habitual es que distintos factores actúen a la vez y que sus efectos se superpongan.
Por eso este modelo resulta especialmente útil cuando queremos pasar de una visión simplificada a una más matizada. Permite construir predicciones incorporando diferentes dimensiones del problema: variables económicas, operativas, sociales o temporales, según el contexto.
En la práctica, esto lo convierte en una herramienta muy poderosa. Podemos estimar el salario en función de la experiencia y la formación, prever ventas a partir del precio, la publicidad y la estacionalidad, o anticipar un coste hospitalario combinando actividad, plantilla y absentismo. El modelo no lo explica todo, pero suele capturar mucho más que una regresión con una sola variable.
Qué nos permite interpretar
Uno de los grandes atractivos de la regresión lineal múltiple es que no sólo predice, sino que también ayuda a pensar.
Cada coeficiente ofrece una interpretación sustantiva: nos dice cuál es el efecto promedio asociado a una variable una vez descontada la influencia de las otras. Esto permite responder preguntas más interesantes que una simple asociación bruta. No preguntamos sólo si dos variables están relacionadas, sino cuánto cambia una cuando la otra varía en un contexto donde intervienen más factores.
Esa capacidad de aislar efectos es una de las razones por las que la regresión múltiple ocupa un lugar tan central en estadística, economía, ciencias sociales, epidemiología y análisis aplicado. Es un modelo que no se limita a describir patrones; también organiza el razonamiento causal, aunque siempre con prudencia.
Las condiciones del modelo
Como todo modelo estadístico, la regresión lineal múltiple descansa sobre varias suposiciones.
- Que la relación entre la variable objetivo y las variables explicativas puede aproximarse razonablemente de forma lineal.
- Que los errores son independientes, que la varianza del error es relativamente constante y que no existe una colinealidad excesiva entre las variables explicativas. Esta última cuestión es especialmente importante en la regresión múltiple: cuando dos o más variables contienen información muy parecida, separar sus efectos se vuelve difícil e inestable.
También seguimos necesitando cierto cuidado al interpretar los resultados. Añadir más variables no garantiza automáticamente un mejor modelo. A veces sólo añade ruido, complejidad o una falsa sensación de control. Como ocurre a menudo en análisis de datos, más información no siempre significa más comprensión.
Cuándo tiene sentido usarla
La regresión lineal múltiple tiene sentido cuando sospechamos que el fenómeno que queremos estudiar depende de varios factores relevantes y cuando nos interesa mantener un equilibrio entre capacidad predictiva e interpretabilidad.
Suele ser un paso natural después de la regresión lineal simple. Una vez comprobado que una sola variable no basta para capturar adecuadamente el comportamiento de Y, el siguiente movimiento lógico es incorporar otras variables que puedan mejorar la explicación del fenómeno.
Por eso es uno de los modelos más utilizados como base en proyectos de predicción cuantitativa. Antes de pasar a algoritmos más opacos o complejos, suele ser muy útil construir primero una regresión múltiple bien pensada. Muchas veces ofrece ya una combinación excelente de claridad, robustez y utilidad práctica.
Una reflexión final
La regresión lineal múltiple parte de una intuición profundamente humana: casi nada importante ocurre por una sola causa. Vivimos rodeados de fenómenos donde distintos factores empujan al mismo tiempo, a veces en la misma dirección y a veces en direcciones opuestas.
Este modelo intenta traducir esa complejidad a un lenguaje ordenado. No lo hace reproduciendo toda la riqueza del mundo, sino reduciéndola a una estructura comprensible. En eso reside su valor, pero también su límite. Porque incluso cuando incorporamos muchas variables, siempre queda algo fuera: lo no observado, lo incierto, lo irreductible.
Tal vez esa sea una de las enseñanzas más interesantes de la predicción cuantitativa. Mejorar un modelo no consiste en eliminar por completo la incertidumbre, sino en aprender a convivir con ella de una manera más lúcida. La regresión lineal múltiple no nos entrega una verdad definitiva sobre la realidad, pero sí una forma más disciplinada de pensarla cuando sabemos que una sola explicación nunca es suficiente.
En el próximo artículo
En el siguiente post aplicaremos la regresión lineal múltiple a un caso real de predicción cuantitativa en el ámbito hospitalario: la predicción mensual de nuevas bajas maternales de trabajadoras.
Veremos cómo una variable aparentemente simple depende en realidad de distintos factores que actúan a la vez, y cómo un modelo puede ayudarnos a ordenar esa complejidad para anticipar mejor lo que ocurrirá en los próximos meses.
El proyecto completo estará disponible en un repositorio reproducible en GitHub, donde se podrá seguir todo el proceso: construcción del dataset, exploración de los datos, estimación del modelo y evaluación de su capacidad predictiva.

Mas allá de la dificultad, para mi, de entender las formulas matemáticas expuestas, muy interesante.
Me gustaMe gusta