Introducción
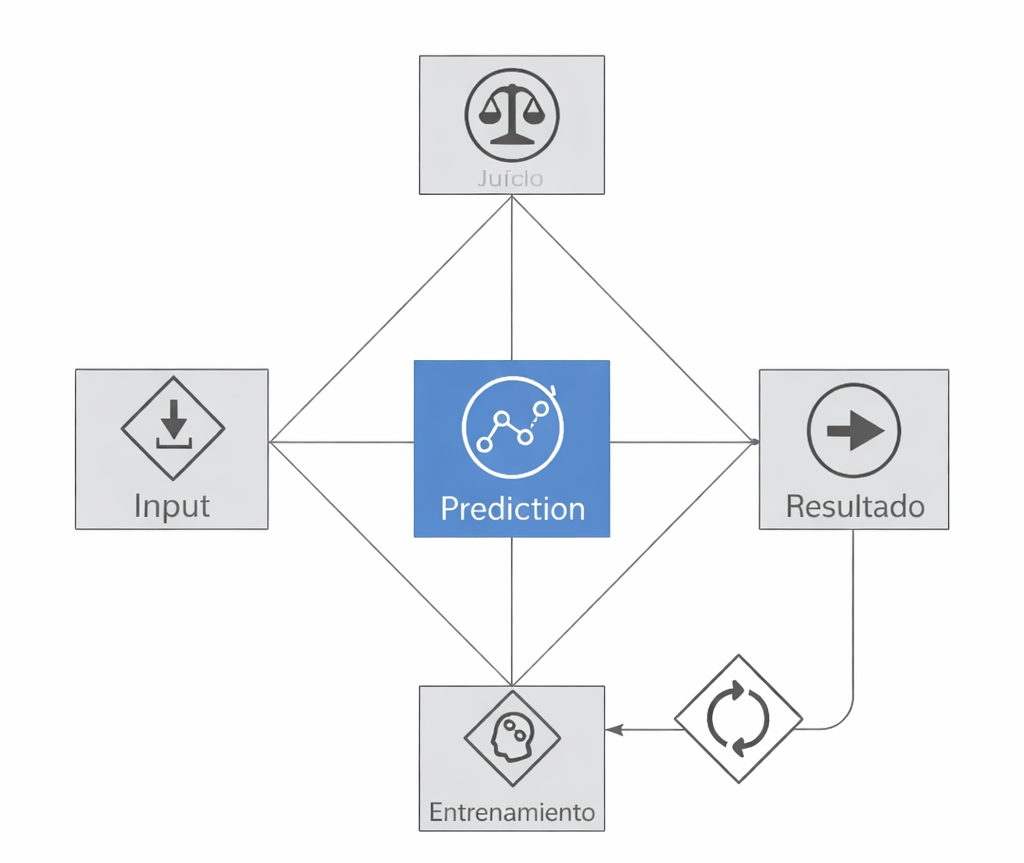
Prediction Machines: The Simple Economics of Artificial Intelligence, publicado en 2018 por Ajay Agrawal, Joshua Gans y Avi Goldfarb, parte de una idea tan simple como potente: el principal impacto de la inteligencia artificial no es que las máquinas “piensen”, sino que reducen drásticamente el coste de la predicción. Y dado que toda decisión incorpora algún tipo de predicción, este abaratamiento tiene consecuencias económicas de gran alcance.
El libro se publicó cuatro años antes del lanzamiento de ChatGPT, anticipándose al auge masivo de la IA generativa y al debate actual sobre su impacto. En un momento en el que la IA aún se percibía como una tecnología especializada, los autores ya señalaban que el verdadero cambio no vendría de aplicaciones llamativas, sino de la incorporación silenciosa de la predicción barata en millones de decisiones cotidianas.
Desde una perspectiva económica y pragmática, la IA se presenta como una continuación de avances previos —como las hojas de cálculo o los sistemas de optimización— que transformaron la toma de decisiones al reducir costes. La diferencia ahora es la escala: pequeñas mejoras en precisión, aplicadas de forma sistemática, generan un valor enorme.
A lo largo del libro, esta tesis se desarrolla en tres grandes bloques: qué es la predicción desde el punto de vista económico, cómo su abaratamiento transforma decisiones y organizaciones, y qué implicaciones estratégicas se derivan de un mundo donde predecir es cada vez más barato, pero el juicio humano sigue siendo escaso y valioso.
Seguir leyendo «Reseña del libro «Máquinas Predictivas: La economía simple de la Inteligencia Artificial»»