En predicción cuantitativa, el primer reto no suele ser elegir un algoritmo complicado, sino formular bien el problema. Antes de entrenar un modelo, hay que decidir qué queremos predecir, cómo vamos a medirlo y qué información puede ayudarnos a anticiparlo.
Con esa idea he preparado un nuevo proyecto en GitHub aplicado a un problema de gestión de personal hospitalario: la predicción mensual de nuevas bajas maternales equivalentes de trabajadoras de un hospital. La pregunta es concreta: ¿podemos estimar cuántas nuevas bajas maternales equivalentes se producirán cada mes entre las trabajadoras de un hospital usando datos agregados sobre plantilla, estabilidad contractual, estructura familiar aproximada y riesgo durante el embarazo?
El objetivo no es predecir decisiones individuales ni explicar la maternidad como fenómeno personal. El proyecto se centra en algo más práctico: construir una estimación mensual agregada que pueda ayudar a planificar sustituciones, prever carga organizativa y reducir parte de la incertidumbre en la gestión de personal.
1. De una pregunta operativa a una variable objetivo
El primer paso del proyecto fue definir qué significaba realmente “prever maternidades”. Una opción sencilla habría sido contar el número de bajas maternales nuevas cada mes. Pero ese indicador tiene un problema: no todas las bajas que empiezan en un mes generan el mismo impacto mensual.
Una maternidad que empieza el día 1 afecta a todo el mes. Una que empieza el día 28 apenas tiene impacto en ese mes, aunque se arrastre a los siguientes. Por eso decidí trabajar con una variable llamada mat_eq_nuevas_mes, que mide las nuevas maternidades en términos equivalentes: los días de baja maternal nueva generados dentro del mes divididos por los días naturales de ese mes.
Así, si una baja maternal empieza el día 16 de un mes de 30 días, aporta 15 días dentro de ese mes. Su valor equivalente será 15/30 = 0,5. Esta definición permite capturar mejor la intensidad mensual del fenómeno que un simple recuento de casos.
2. Construir un dataset con señales potencialmente predictivas
Una vez definida la variable objetivo, el siguiente paso fue construir un dataset mensual. Cada fila representa un mes e incluye, por un lado, el valor de las nuevas maternidades equivalentes y, por otro, un conjunto de variables agregadas que podrían ayudar a anticiparlo.
Agrupé esas variables en cuatro bloques:
- Tamaño de la población expuesta: la plantilla equivalente de mujeres de 25 a 40 años (
ppef_mujeres_25_40). - Características laborales: el porcentaje de trabajadoras indefinidas dentro de ese grupo (
pct_indef_25_40). - Estructura familiar aproximada: una proxy basada en la proporción de trabajadoras con hijos menores declarados en nómina (
pct_amb_fill_25_40). - Riesgo durante el embarazo: variables que recogen cuántas situaciones de riesgo estaban activas al cierre del mes anterior y desde hacía cuánto tiempo.
Este último bloque era especialmente interesante. En muchos casos, una situación de riesgo durante el embarazo puede preceder a una baja maternal. Por eso se incluyeron variables como RE_activo_total_lag1, RE_activo_0_1m_lag1, RE_activo_1_2m_lag1, RE_activo_2_3m_lag1 y RE_activo_3m_plus_lag1.
Además, se construyó la variable RE_ponderado, que resume esas situaciones activas de riesgo en un único indicador. La idea fue dar más peso a los riesgos con más antigüedad, porque podían estar más cerca de transformarse en una baja maternal. Después, este indicador se retrasó uno, dos y tres meses (RE_ponderado_lag1, RE_ponderado_lag2 y RE_ponderado_lag3) para comprobar qué desfase aportaba más señal predictiva.
Los datos publicados en el repositorio son ficticios. No buscan representar una institución concreta ni exponer información sensible. Su función es didáctica: permitir seguir el flujo completo del proyecto, desde el dataset inicial hasta el modelo final y la aplicación interactiva.
3. Antes de modelar, mirar los datos
El primer notebook del proyecto (01_data_cleaning_eda.ipynb) está dedicado a la limpieza y al análisis exploratorio. Esta fase puede parecer menos atractiva que el modelado, pero es fundamental. Antes de ajustar una regresión, hay que comprobar si los datos tienen sentido.
En esta etapa se revisan tipos de datos, valores nulos, formato de fechas, orden temporal y estadísticas descriptivas. También se visualiza la evolución mensual de la variable objetivo y se compara con variables como la plantilla equivalente o el riesgo durante el embarazo ponderado.
El objetivo no es demostrar todavía que existe una relación predictiva, sino observar si hay señales plausibles. ¿La variable objetivo tiene variabilidad suficiente? ¿Las variables explicativas se mueven de forma razonable? ¿Existen correlaciones que justifiquen probar un modelo? ¿Hay colinealidad excesiva entre predictores?
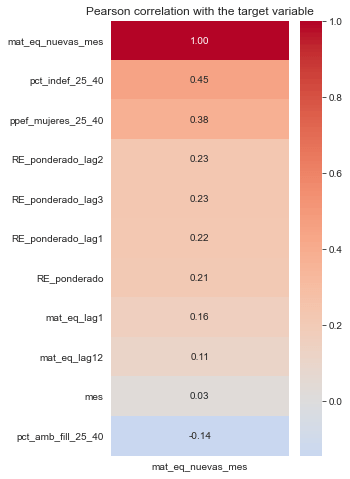
Para ello se utilizan herramientas sencillas: gráficos temporales, dispersión entre variables, correlaciones de Pearson y Spearman, matriz de correlación entre predictores y VIF. Este paso es importante porque ayuda a evitar una tentación habitual: entrenar modelos antes de entender mínimamente el terreno sobre el que estamos trabajando.
4. Por qué usar regresión lineal múltiple
A diferencia del proyecto anterior de regresión lineal simple, aquí no hay una única variable explicativa. La aparición mensual de nuevas maternidades equivalentes puede depender de varios factores simultáneos: tamaño de la población expuesta, estabilidad contractual, composición familiar aproximada, señales adelantadas de riesgo durante el embarazo e incluso cierta estacionalidad.
Por eso el modelo natural para este proyecto es una regresión lineal múltiple. La idea es extender la lógica de la regresión simple: en lugar de explicar una variable objetivo a partir de una sola variable, intentamos explicarla a partir de varias.
La ventaja de este enfoque es que sigue siendo interpretable. No estamos usando una caja negra, sino un modelo que permite analizar qué variables entran, con qué signo, con qué peso y con qué estabilidad. En un contexto de gestión, esa interpretabilidad es casi tan importante como el error predictivo.
En el segundo notebook (02_modeling.ipynb) se comparan dos implementaciones: LinearRegression de scikit-learn y OLS de statsmodels. La primera es cómoda para predicción y despliegue. La segunda es especialmente útil para interpretar coeficientes y revisar el modelo desde una perspectiva estadística.
5. Probar combinaciones sin perder el criterio
Una parte importante del proyecto consiste en probar diferentes combinaciones de variables. Pero no se trata de lanzar todas las posibilidades sin pensar. Eso podría llevar a elegir un modelo que funciona bien por casualidad en el periodo de prueba, pero que no generaliza.
Por eso el notebook de modelado genera combinaciones de variables de forma controlada. Se limita el número máximo de predictores y se evitan combinaciones redundantes, como incluir varios retardos muy parecidos del mismo indicador de riesgo durante el embarazo.
Después, cada combinación se evalúa con una división temporal train/test. Esto es importante porque estamos trabajando con una serie mensual. No tendría sentido mezclar meses aleatoriamente: en un problema de predicción real, entrenamos con el pasado y queremos anticipar el futuro.
La métrica principal es el MAE, el error absoluto medio, porque se interpreta en las mismas unidades que la variable objetivo. Si el MAE es 1,2, significa que el modelo se equivoca de media en unas 1,2 maternidades equivalentes mensuales. Esa lectura es mucho más útil operativamente que una métrica difícil de traducir.
6. Un modelo sólo sirve si mejora reglas simples
El tercer notebook (03_baselines_and_model_comparison.ipynb) aborda una pregunta que considero esencial: ¿el modelo mejora realmente a una regla simple?
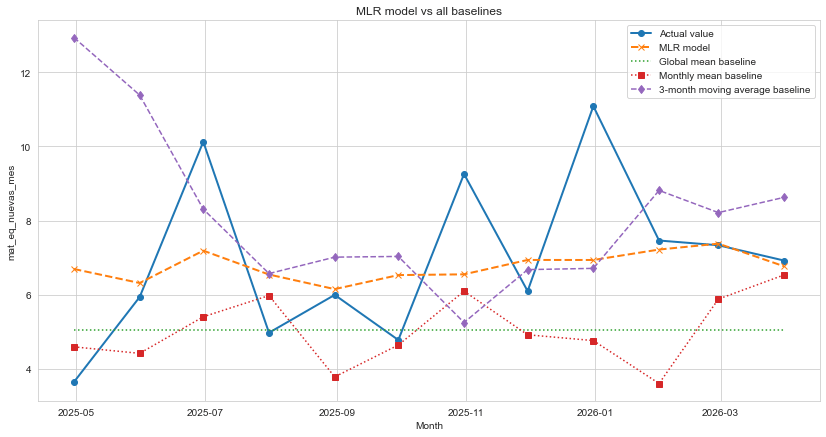
Esta comparación contra baselines es una de las partes más importantes del proyecto. A veces un modelo parece sofisticado, pero no mejora una media histórica, el valor del mes anterior o el mismo mes del año anterior. En ese caso, quizá el modelo sea interesante como ejercicio, pero no como herramienta predictiva.
Por eso se comparó la regresión lineal múltiple contra varios baselines: media histórica global, media histórica por mes, último valor observado, mismo mes del año anterior y media móvil de tres meses. La lógica es sencilla: si el modelo no supera estas referencias, no merece mucha confianza.
En este proyecto, el modelo final sí mejora sustancialmente los baselines simples (un 32% mejor que el mejor baseline). Esa mejora no significa que el modelo sea perfecto ni que pueda anticipar cada mes con precisión absoluta. Significa algo más razonable: que las variables incluidas aportan señal útil y permiten reducir el error frente a reglas ingenuas.
7. Llevar el modelo a una app interactiva
El proyecto no termina en los notebooks. También incluye una pequeña aplicación desarrollada con Streamlit (app.py). Su objetivo es permitir una interacción más directa con el modelo.
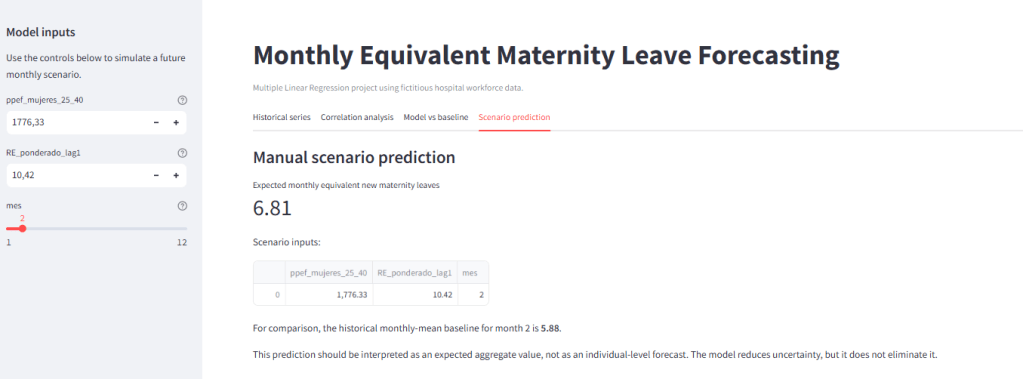
La app permite visualizar la serie histórica, consultar correlaciones, comparar predicciones con valores reales y simular escenarios introduciendo manualmente valores de algunas variables explicativas. Por ejemplo, se pueden modificar la plantilla equivalente de mujeres de 25 a 40 años, el indicador de riesgo durante el embarazo con retardo y el mes de predicción.
Esta parte me parece especialmente importante porque muestra el paso entre análisis y herramienta. En el notebook se razona, se explora y se evalúa. En la aplicación, el modelo se convierte en algo que puede usarse para pensar escenarios.
Naturalmente, la app no convierte el modelo en un sistema productivo completo. Es una primera versión didáctica. Pero sirve para mostrar cómo un modelo relativamente sencillo puede pasar del análisis a una herramienta interactiva y comprensible.
Reflexión final
Este proyecto me interesa porque muestra una idea central de la predicción cuantitativa: la utilidad de un modelo no depende sólo de su complejidad. Depende de que la pregunta esté bien formulada, la variable objetivo tenga sentido, las variables explicativas estén justificadas y el resultado mejore alternativas simples.
La regresión lineal múltiple no elimina la incertidumbre. Tampoco convierte un fenómeno humano y organizativo en algo perfectamente predecible. Pero puede ayudar a ordenar la información disponible y transformarla en una estimación útil.
En este caso, el valor del proyecto no está únicamente en el modelo final. Está en el recorrido completo: definir qué significa una maternidad equivalente, construir un dataset mensual, explorar relaciones, probar combinaciones de variables, comparar con baselines y desplegar una app sencilla.
Al final, predecir no es adivinar. Es reducir incertidumbre de forma disciplinada. Y a veces, una regresión lineal múltiple bien construida puede ser suficiente para empezar a hacerlo.
