Cuando pensamos en predicción, lo habitual es imaginar datos, modelos y probabilidades. Intentos de reducir la incertidumbre para tomar mejores decisiones. Pero hay una cuestión más profunda: ¿de dónde nace realmente esa necesidad de anticipar el futuro?
El filósofo Ernst Bloch ofrece una respuesta sugerente: el ser humano no vive solo en el presente, sino proyectado constantemente hacia lo que aún no existe. Antes de calcular escenarios, ya imaginamos posibilidades. Antes de construir modelos, ya vivimos orientados hacia el futuro.
Cuando se habla de inteligencia artificial, muchas veces se empieza por el modelo. Pero antes de elegir una técnica conviene hacerse una pregunta más importante: qué decisión queremos mejorar.
Para eso resulta útil el AI canvas, una herramienta explicada en el libro Máquinas predictivas. Su función es muy simple: ayudar a ordenar un caso de uso de IA antes de construirlo. En lugar de quedarse en una idea vaga como “aquí podríamos usar IA”, obliga a concretar qué queremos predecir, para qué serviría esa predicción, qué datos harían falta y cómo sabríamos si el sistema funciona bien.
En 2016 ocurrió algo que, durante décadas, muchos expertos consideraban improbable: una máquina fue capaz de derrotar a uno de los mejores jugadores del mundo en un juego que simbolizaba la intuición humana.
El sistema era AlphaGo, desarrollado por DeepMind, y su oponente era el campeón surcoreano Lee Sedol.
A primera vista, podría parecer simplemente otro avance tecnológico. Pero lo que ocurrió en aquellas partidas fue algo más profundo: por primera vez, una máquina no solo competía con un humano en un terreno complejo, sino que lo hacía de una forma que desafiaba nuestra propia manera de pensar.
A comienzos de año planteé tres predicciones para 2026 siguiendo un enfoque explícitamente probabilístico: no tanto para acertar una cifra concreta, sino para dejar claro el razonamiento detrás de cada escenario. Como se prometió entonces, el objetivo no era solo predecir, sino también revisar.
Tras el cierre del primer trimestre, ya disponemos de nueva información relevante —tanto en el ámbito macroeconómico como en el mercado inmobiliario y en el contexto político— que justifica actualizar esas previsiones. En las siguientes secciones reviso cada una de las tres predicciones iniciales, ajustando la tasa base, los motores y los frenos para reflejar mejor el estado actual del mundo.
Tipo de evento: La inflación media anual (IPC) registrada en 2026 en España.
Predicción: un 62% de probabilidad que suba más de un 8%.
Evento
La variación anual media del precio de compra de la vivienda en España durante el año 2026.
El evento se considerará evaluado una vez disponibles los datos definitivos correspondientes a 2026 publicados por las fuentes estadísticas de referencia (INE, Ministerio de Vivienda u organismos equivalentes).
Tasa base
La previsión de enero partía de una tasa base operativa del 6,5%, coherente con un mercado ya tensionado pero todavía interpretable como una prolongación del régimen anterior.
La información del primer trimestre obliga a revisar esa referencia al alza, aunque sin llevarla a un escenario extremo. Por un lado, los precios siguen mostrando una aceleración muy intensa: El País recoge una subida interanual del 14,3% en el primer trimestre de 2026 y sitúa el euríbor de marzo en el 2,565%. Por otro, empiezan a aparecer señales de enfriamiento en la actividad: los notarios informaron de una caída del 11,4% en las compraventas de enero, hasta 49.685 operaciones.
La lectura conjunta sugiere un mercado todavía muy alcista en precios, pero con una demanda que empieza a mostrar más fricción. Con ese equilibrio, la nueva tasa base operativa para esta revisión pasa a ser el 8,0%.
Ajustes cualitativos
Motores
Escasez estructural de oferta, especialmente en áreas urbanas tensionadas: Sigue siendo el motor principal. La intensidad de las subidas observadas encaja mejor con un problema de oferta persistente que con un episodio coyuntural. Impacto estimado: 70 % – 85 %
Concentración de la demanda en determinadas zonas geográficas: La presión continúa muy focalizada en grandes ciudades, costa e islas, donde la oferta responde peor y la accesibilidad empeora más rápido. Impacto estimado: 65 % – 80 %
Percepción de la vivienda como activo relativamente seguro: La vivienda mantiene parte de su atractivo como refugio relativo en un entorno de alquileres altos, incertidumbre y escasez. Impacto estimado: 50 % – 65 %
Inercia de expectativas tras varios años de subidas intensas: Sigue actuando, pero con algo menos de fuerza. La caída de compraventas sugiere que el mercado puede estar acercándose más a una fase de menor aceleración que a una nueva espiral alcista. Impacto estimado: 50 % – 65 %
Frenos
Coste de financiación y esfuerzo financiero de los hogares: Gana peso. El repunte del euríbor y la caída de compraventas e hipotecas apuntan a una demanda más sensible al coste del dinero. Impacto estimado: 40 % – 55 %
Límites de renta y ahorro disponibles para nuevos compradores: También se refuerza. El deterioro de la accesibilidad empieza a limitar con más claridad la capacidad de absorción del mercado. Impacto estimado: 45 % – 60 %
Incertidumbre regulatoria y fiscal con impacto desigual: Se mantiene sin grandes cambios. Su efecto sigue siendo heterogéneo y secundario frente a la dinámica general del mercado. Impacto estimado: 25 % – 40 %
Posible saturación de demanda en segmentos específicos: Gana importancia. La caída de actividad sugiere que algunos segmentos pueden estar empezando a frenarse antes que el precio medio. Impacto estimado: 30 % – 45 %
Predicción probabilística
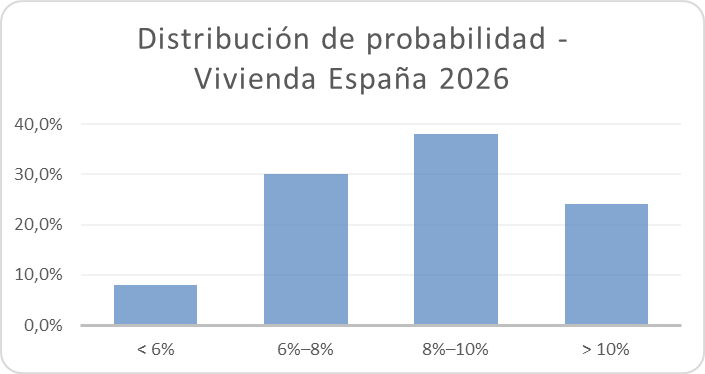
Distribución subjetiva de probabilidad para la variación anual del precio de la vivienda en 2026:
• Subida inferior al 6 % → 8 % • Subida entre 6 % y 8 % → 30 % • Subida entre 8 % y 10 % → 38 % • Subida superior al 10 % → 24 %
La probabilidad implícita de que la subida supere el 8 % se sitúa en el 62 %.
Metodología y reproducibilidad
El cálculo completo de probabilidades y escenarios está disponible en un archivo Excel adjunto, editable y reproducible, que recoge:
• Tasa base utilizada • Ajustes cualitativos • Combinación de escenarios • Normalización de probabilidades
Revisión de la predicción
La actualización introduce un matiz relevante en la distribución. La fuerte subida de precios observada en el primer trimestre obliga a revisar al alza la previsión de enero, desplazando el escenario central hacia el rango 8%–10%.
Sin embargo, la caída de compraventas introduce una señal nueva: el mercado empieza a mostrar signos de enfriamiento en la actividad. Esto no revierte la tendencia alcista, pero sí reduce la probabilidad de los escenarios más extremos.
La lección es clara: en el mercado inmobiliario, los ajustes no son simultáneos. La actividad puede frenarse antes que los precios, lo que obliga a vigilar no solo cuánto sube la vivienda, sino también cuánta capacidad real queda para sostener ese crecimiento.
A menudo se habla de predicción cuantitativa como si fuera un terreno reservado a modelos complejos, librerías sofisticadas y sistemas difíciles de explicar. Pero no siempre hace falta empezar por ahí. De hecho, muchas veces creo que ocurre lo contrario: para entender bien qué significa predecir con datos, conviene empezar por un modelo pequeño, transparente y fácil de interpretar.
Por eso he querido compartir en GitHub un proyecto completo construido alrededor de una pregunta muy concreta: cómo estimar cuántos días de contratos temporales de cobertura pueden generarse cuando aumenta el absentismo laboral por incapacidad temporal(IT). No he preparado este repositorio para presentar un gran sistema productivo ni una solución definitiva. Lo he hecho para mostrar, de forma reproducible, cómo puede utilizarse una regresión lineal simple como método de predicción cuantitativa.
La idea del proyecto no es solo enseñar una ecuación. Es enseñar un recorrido. Cómo se parte de una pregunta real, cómo se traduce esa pregunta a variables medibles, cómo se preparan los datos, cómo se comprueba si la relación tiene sentido y cómo se convierte finalmente el modelo en una pequeña aplicación utilizable. En el fondo, lo que me interesaba compartir no era solo el resultado, sino el proceso.
En muchos contextos cotidianos observamos relaciones entre variables: más horas de estudio suelen asociarse con mejores notas, viviendas más grandes suelen tener precios más altos, y más entrenamiento suele mejorar el rendimiento deportivo.
La pregunta que surge de forma natural es sencilla pero profunda: ¿podemos cuantificar estas relaciones para anticipar lo que ocurrirá en el futuro?
Uno de los modelos más simples y elegantes para responder a esta pregunta es la regresión lineal simple. A pesar de su aparente sencillez, este modelo constituye uno de los pilares fundamentales de la predicción cuantitativa.
Cuando hoy escuchamos palabras como machine learning o inteligencia artificial, es fácil imaginar algoritmos sofisticados trabajando sobre enormes bases de datos. Sin embargo, la idea fundamental detrás de muchos de estos modelos es mucho más antigua. En el fondo, todos intentan responder una pregunta sencilla: si una variable cambia, cómo cambia otra.
Responder a esa pregunta con números ha sido una preocupación constante durante siglos. Mucho antes de que existiera la estadística formal, científicos, comerciantes y astrónomos ya intentaban encontrar patrones que permitieran anticipar resultados.
La regresión moderna es el resultado de ese largo esfuerzo intelectual. Su historia no es una ruptura tecnológica reciente, sino una evolución gradual de ideas que comienzan con cálculos muy simples y terminan en los algoritmos de aprendizaje automático actuales.
Cuando se habla de inteligencia artificial o aprendizaje automático, muchas veces se piensa inmediatamente en algoritmos complejos. Sin embargo, en la práctica los modelos son solo una pequeña parte del trabajo.
La predicción cuantitativa no consiste simplemente en “aplicar un algoritmo”. Consiste en recorrer un proceso estructurado que transforma datos en conocimiento útil para tomar decisiones.
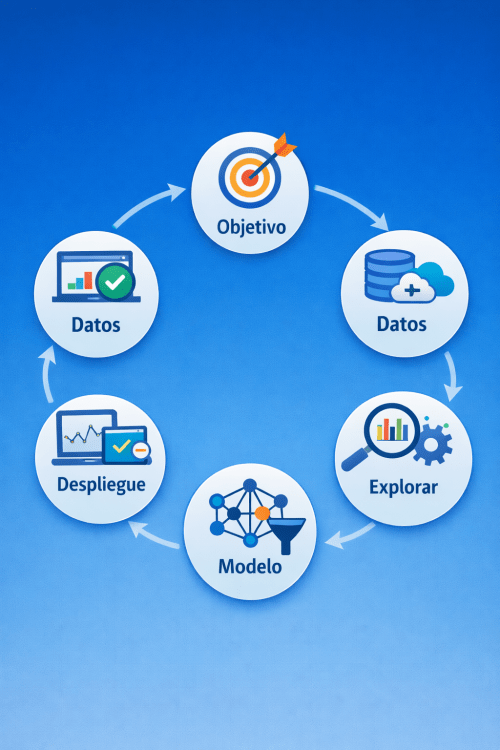
Ese proceso es lo que en ciencia de datos se conoce como el ciclo de vida de un proyecto de Machine Learning.
Aunque los modelos puedan ser muy diferentes —desde una simple regresión hasta sistemas avanzados de deep learning—, casi todos los proyectos siguen una lógica muy similar.
En términos generales, este recorrido puede resumirse en seis etapas:
Definir el objetivo
Adquirir los datos
Explorar la información
Preparar el dataset
Construir el modelo
Desplegar y monitorizar
En este post veremos brevemente qué ocurre en cada una de estas fases. En futuras publicaciones iré mostrando proyectos reales que siguen exactamente esta misma estructura. Estos nos servirán de ejemplo de los modelos de predicción cuantitativa más utilizados
En un post anterior clasificábamos los métodos de previsión en dos grandes familias: cuantitativos y cualitativos. Dentro de los cualitativos podemos distinguir aquellos basados en juicio individual (opinión experta, analogías históricas, escenarios narrativos) y aquellos que intentan estructurar el juicio colectivo para reducir sesgos. El método Delphi pertene a esta segunda categoria.
No es predicción basada en datos en sentido estricto porque no parte de series temporales ni modelos matemático pero tampo es simple intuición. Es, probablemente, el intento más sofisticado del siglo XX de convertir el juicio experto en una herramienta sistemática de predicción.
Este método nació además en un contexto donde equivocarse podía significar una guerra nuclear.