Continuamos con esta serie de post donde exploramos las ideas clave del libro “Pensar rápido, pensar despacio” de Daniel Kahneman —una obra fundamental para entender cómo pensamos, decidimos… y, por extensión, cómo predecimos— y hoy hablaremos de uno de los sesgos más sutiles, pero también más poderosos: el sesgo de disponibilidad.
¿Qué es el sesgo de disponibilidad?
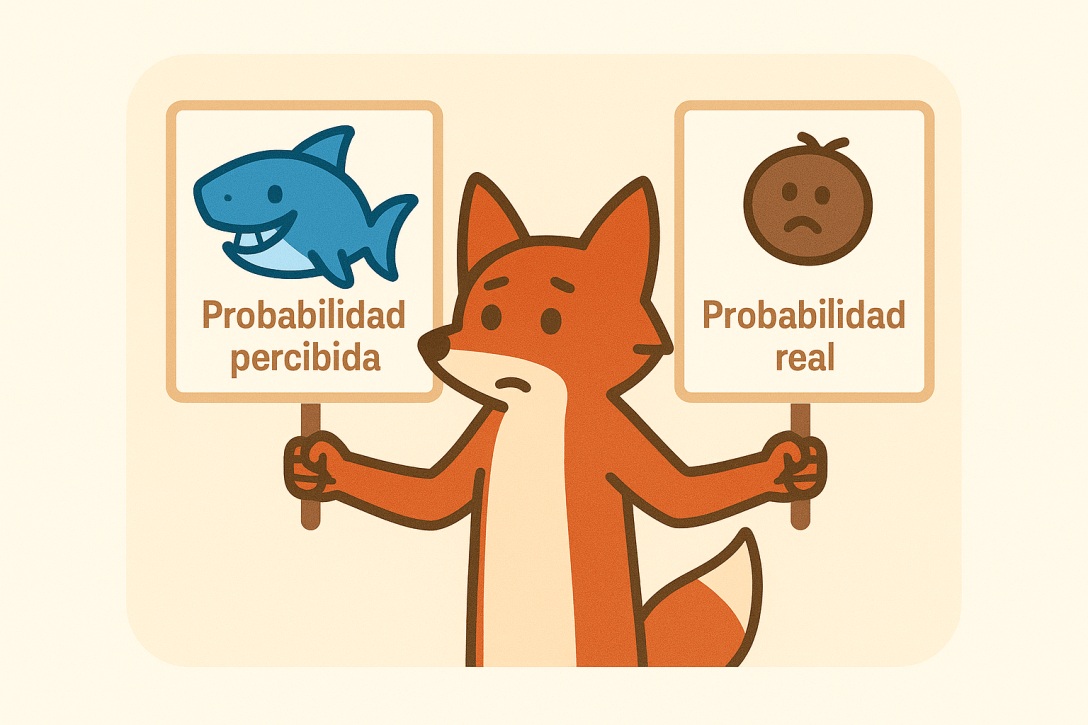
El sesgo de disponibilidad es la tendencia que tenemos a juzgar la probabilidad o frecuencia de un evento según la facilidad con la que recordamos ejemplos de él. En otras palabras: cuanto más fácilmente recordamos algo, más probable nos parece que sea.
No estimamos con datos, sino con nuestros recuerdos y éstos —como bien explica Kahneman— no son un registro fiel del mundo, sino un archivo sesgado por la emoción, la atención y los medios.
Un ejemplo clásico del libro
Kahneman y Tversky realizaron un experimento muy revelador: preguntaron a un grupo de personas si, en inglés, hay más palabras que empiecen por la letra K o más palabras que tengan la K como tercera letra.
La mayoría respondió que hay más palabras que empiezan por K, porque es más fácil recordar ejemplos como kite o king que pensar en palabras con K en la tercera posición (make, bake…). Sin embargo, la respuesta correcta era la contraria: hay más palabras con “K” en la tercera posición (¡3 veces más!).
El problema no es la falta de inteligencia, sino el mecanismo del Sistema 1, el pensamiento rápido e intuitivo: confunde “lo fácil de recordar” con “lo frecuente en el mundo”.
Seguir leyendo «Por qué sobreestimamos los tiburones y subestimamos los cocos: el poder del sesgo de disponibilidad»