En el post anterior vimos que la predicción no siempre empieza con datos y modelos: a veces lo más razonable es recurrir a estrategias cualitativas. Pero cuando el fenómeno es lo bastante estable, repetible y medible, la predicción cuantitativa ofrece algo muy valioso: un lenguaje común para comparar, evaluar y mejorar.
Ahora bien, dentro de la predicción cuantitativa conviene hacer una distinción fundamental porque no todos los modelos numéricos funcionan igual.
- Algunos resuelven una estructura matemática estimada a partir de los datos y producen una predicción directa.
- Otros, en cambio, recrean el sistema múltiples veces mediante simulación, generando dinámicas posibles y distribuciones emergentes.
Este post se centra en la primera familia: la predicción cuantitativa analítica.
1. ¿Cuándo conviene usar predicción cuantitativa analítica?
Este enfoque funciona especialmente bien cuando:
- El fenómeno es relativamente estable: No cambia su estructura cada semana.
- Dispones de datos históricos razonables: No necesitas millones de observaciones, pero sí suficiente señal para estimar parámetros.
- Buscas una predicción clara y operativa: Un número, una probabilidad, una distribución estimada.
- El sistema no tiene dinámicas altamente no lineales o emergentes: No estás modelando un ecosistema caótico ni una guerra.
En un contexto profesional sanitario —por ejemplo, previsión de gasto de personal o bajas médicas en un hospital— este enfoque suele ser el punto de partida natural porque no necesitas simular el sistema sanitario completo y necesitas proyectar algo con cierta estabilidad estructural. En estos casos los modelos analíticos brillan.
2. Tipos de modelos cuantitativos analíticos
2.1 Modelos de regresión
Los modelos de regresión se utilizan cuando queremos explicar una variable (la Y) a partir de otras variables observables (las X). La pregunta típica es: ¿de qué depende esto?
Por ejemplo: ¿cómo influyen la edad, la categoría profesional y la estacionalidad en la probabilidad de baja médica? Aquí el tiempo puede aparecer como una variable más, pero no es el eje central. Lo importante son las relaciones entre variables.
Estos modelos estiman cuánto cambia la variable objetivo cuando cambian las explicativas. Algunos ejemplos habituales son la regresión lineal (simple o múltiple), los modelos logísticos cuando la variable es binaria, o los modelos de Poisson cuando trabajamos con conteos.
Son especialmente útiles cuando queremos interpretar efectos y entender mecanismos.
2.2 Modelos de series temporales
Los modelos de series temporales se emplean cuando la información clave está en la propia evolución histórica de la variable. La pregunta ya no es tanto ¿de qué depende?, sino ¿qué patrón sigue en el tiempo?
Por ejemplo: ¿cómo han evolucionado las bajas mensuales en los últimos cinco años? Aquí importa la tendencia, la estacionalidad, los ciclos o los shocks pasados. No estamos explicando el fenómeno mediante variables externas; estamos proyectando su estructura temporal.
Entre los modelos más conocidos están el modelo ingenuo (naive), los distintos enfoques ARIMA o herramientas más automatizadas como Prophet. Son especialmente potentes cuando el pasado contiene suficiente señal repetitiva.
2.3 Modelos estructurales econométricos
En este grupo entran los modelos que parten de una teoría explícita sobre cómo funciona el sistema. No solo observamos datos: planteamos una arquitectura basada en hipótesis.
Por ejemplo, si queremos modelar el impacto de un cambio normativo, de un incentivo salarial o de una reforma organizativa, necesitamos representar las relaciones causales que la teoría sugiere. La teoría define la estructura; los datos se utilizan para estimar sus parámetros.
Aquí encontramos modelos de ecuaciones simultáneas, modelos macroeconómicos estructurales o VAR estructurales (SVAR). Son más exigentes en supuestos, pero permiten interpretar resultados dentro de un marco conceptual claro.
2.4 Modelos de machine learning determinista
Estos modelos se utilizan cuando el número de variables es grande, las relaciones son complejas o no lineales, y la prioridad es la capacidad predictiva más que la interpretación detallada.
A diferencia de los modelos estructurales, no necesitamos especificar la forma exacta de la relación entre variables. El algoritmo aprende esa estructura a partir de los datos. Una vez entrenado, aplica la función aprendida y produce una predicción directa.
Entre los ejemplos más conocidos están los árboles de decisión, Random Forest, Gradient Boosting o redes neuronales. Son especialmente útiles cuando hay mucha información disponible y patrones difíciles de modelar manualmente.
2.5 Modelos bayesianos en enfoque analítico
En este último grupo no cambia necesariamente la forma del modelo (puede ser una regresión, una serie temporal o incluso un modelo estructural). Lo que cambia es el tratamiento de la incertidumbre.
En lugar de obtener un único valor estimado, obtenemos una distribución de resultados plausibles. La predicción deja de ser “un número” y pasa a ser un rango probabilístico con estructura.
Este enfoque resulta especialmente valioso cuando disponemos de pocos datos, cuando queremos incorporar conocimiento previo de forma explícita o cuando la cuantificación precisa de la incertidumbre es central para la decisión.
En contextos como la planificación presupuestaria o sanitaria, esta diferencia no es menor: muchas decisiones no dependen solo del valor esperado, sino del abanico de escenarios razonables.
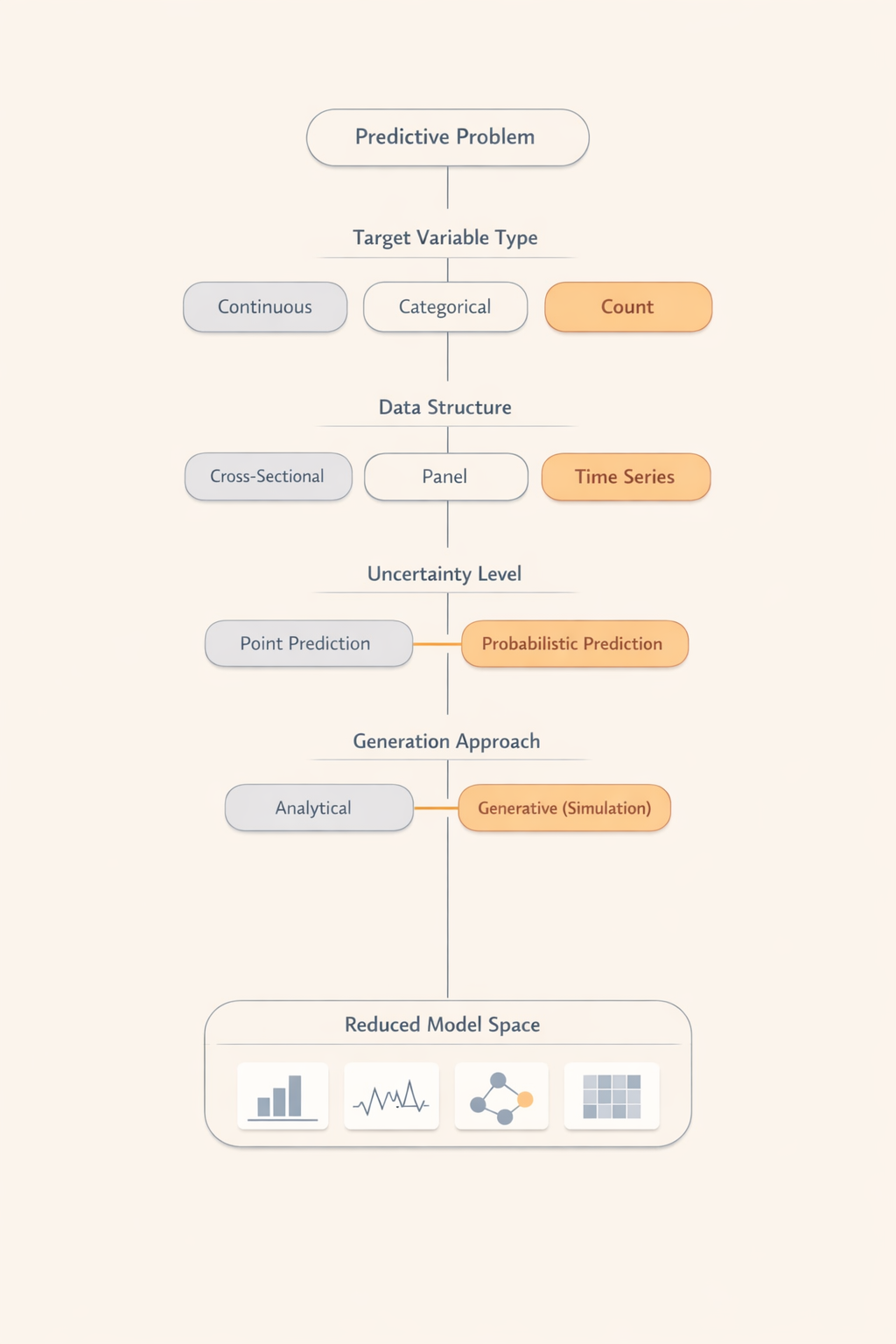
3. ¿Cómo elegir el modelo?
Una forma útil de elegir sin perderse en modelos es hacerlo en este orden:
- Define la variable objetivo: ¿Es continua, categórica o un conteo?
- Mira la estructura: ¿Es una foto, una película por unidad o una serie temporal?
- Decide el nivel de incertidumbre que necesitas: ¿Te basta una cifra o necesitas probabilidades/intervalos?
- ¿Cómo se generará la predicción?
Para facilitar esta decisión, incluyo una infografía descargable con este flujo de preguntas para reducir el espacio de elección de modelos.
Por ejemplo, si queremos prever el número total de bajas laborales mensuales en 2027 para planificar presupuesto y sustituciones, el flujo de preguntas nos guía casi sin darnos cuenta. Primero identificamos que estamos ante un conteo de eventos, no una clasificación. Después observamos que los datos son mensuales y con estacionalidad, lo que nos sitúa en el terreno de las series temporales. A continuación decidimos si necesitamos solo una cifra esperada o una estimación probabilística del riesgo de superar cierto umbral. Y finalmente elegimos si basta con proyectar analíticamente el patrón histórico (por ejemplo, con un SARIMA) o si necesitamos simular múltiples trayectorias para incorporar escenarios adicionales. Antes de hablar de modelos concretos, el espacio de elección ya se ha reducido drásticamente.
Para cerrar
La predicción cuantitativa analítica es una herramienta extraordinariamente útil: permite formalizar el problema, estimar relaciones y obtener proyecciones claras y operativas. Es elegante en su planteamiento y eficiente en su ejecución. Cuando el fenómeno es relativamente estable, suele ofrecer respuestas sólidas y accionables.
Pero no lo puede todo. Este enfoque parte de una estructura definida y la proyecta hacia el futuro. No está pensado para capturar dinámicas emergentes complejas, sistemas altamente adaptativos o interacciones que cambian de forma continua al reaccionar entre sí.
En otras palabras, resuelve un modelo y extiende su lógica.
En la próxima entrega veremos qué ocurre cuando eso no es suficiente. Cuando no basta con proyectar una estructura estimada, sino que necesitamos recrear el sistema, experimentar con escenarios y observar qué dinámicas aparecen. Ahí entramos en otra familia de métodos: la predicción basada en simulación.

{kind=link}