A menudo se habla de predicción cuantitativa como si fuera un terreno reservado a modelos complejos, librerías sofisticadas y sistemas difíciles de explicar. Pero no siempre hace falta empezar por ahí. De hecho, muchas veces creo que ocurre lo contrario: para entender bien qué significa predecir con datos, conviene empezar por un modelo pequeño, transparente y fácil de interpretar.
Por eso he querido compartir en GitHub un proyecto completo construido alrededor de una pregunta muy concreta: cómo estimar cuántos días de contratos temporales de cobertura pueden generarse cuando aumenta el absentismo laboral por incapacidad temporal (IT). No he preparado este repositorio para presentar un gran sistema productivo ni una solución definitiva. Lo he hecho para mostrar, de forma reproducible, cómo puede utilizarse una regresión lineal simple como método de predicción cuantitativa.
La idea del proyecto no es solo enseñar una ecuación. Es enseñar un recorrido. Cómo se parte de una pregunta real, cómo se traduce esa pregunta a variables medibles, cómo se preparan los datos, cómo se comprueba si la relación tiene sentido y cómo se convierte finalmente el modelo en una pequeña aplicación utilizable. En el fondo, lo que me interesaba compartir no era solo el resultado, sino el proceso.
1. Empezar por una pregunta que pueda convertirse en variable
Todo proyecto de predicción cuantitativa empieza mucho antes del modelo. Empieza en el momento en que una intuición se convierte en una pregunta formulable. En este caso, la intuición era bastante sencilla: si aumenta el absentismo por IT, es razonable pensar que también aumente la necesidad de cobertura mediante contratación temporal. Pero una intuición organizativa todavía no es un modelo. Para que lo sea, primero hay que volverla medible.
Eso me llevó a plantear el proyecto en torno a dos variables muy simples. Por un lado, los días de absentismo por IT. Por otro, los días de contratos temporales de cobertura. Elegí trabajar con días y no con número de personas o número de contratos porque me parecía una forma más estable y más interpretable de representar el problema. Los días permiten capturar duración, intensidad y volumen sin depender tanto de cómo esté fragmentada la contratación.
En este sentido, el proyecto quiere mostrar algo que me parece central en estadística aplicada: antes de preguntarnos qué modelo usar, deberíamos preguntarnos qué estamos midiendo exactamente. Muchas veces el verdadero trabajo no consiste en elegir un algoritmo, sino en definir bien las magnitudes. Si esa definición es mala, el resto del proyecto será una prolongación del error. Si es razonable, incluso un modelo muy simple puede resultar útil.
2. Convertir la pregunta en un dataset manejable
Una vez definida la lógica del problema, el siguiente paso consistió en transformarla en un dataset sencillo. En el repositorio he compartido un archivo CSV con tres columnas: la fecha, los días de absentismo por IT y los días de contratos temporales de cobertura. Cada fila representa una observación temporal. La idea era construir una base suficientemente simple como para que cualquiera pudiera abrirla, entenderla y seguir el proyecto sin perderse en estructuras demasiado complejas.
He querido además que los datos publicados sean ficticios. Esto me permite enseñar el flujo completo del proyecto sin depender de datos sensibles ni de contextos administrativos concretos que no tendría sentido exponer públicamente. Me interesaba que el repositorio fuera replicable, legible y útil como ejemplo didáctico. En este caso, la función del dataset no es documentar una realidad institucional concreta, sino servir como soporte para entender el método.
Esto también forma parte del mensaje del proyecto. Cuando compartimos análisis en abierto, no siempre se trata de revelar datos reales. A veces lo importante es compartir la lógica del trabajo. Cómo se estructura la información, cómo se define una variable objetivo, cómo se prepara una tabla para poder modelarla. En cierto modo, este proyecto no pretende decir “así son los datos”, sino “así puede construirse un pequeño problema de predicción cuantitativa”.
3. Antes de ajustar una recta, hay que mirar los datos
Una de las cosas que más me interesaba mostrar con este ejemplo es que un modelo no empieza cuando escribimos LinearRegression(). Empieza antes, en la fase en la que inspeccionamos los datos y tratamos de entender si realmente contienen una relación plausible. Por eso el primer notebook del repositorio (01_data_cleaning_eda.ipynb) está dedicado a la limpieza y al análisis exploratorio.
En esa parte del proyecto reviso cuestiones muy básicas, pero esenciales: si hay fechas mal formadas, si existen duplicados, si faltan valores, si las columnas tienen el tipo adecuado y, sobre todo, si la relación entre las dos variables parece lo bastante clara como para justificar una regresión lineal simple. Eso implica mirar gráficos, observar la evolución temporal y dibujar la nube de puntos entre absentismo y cobertura.
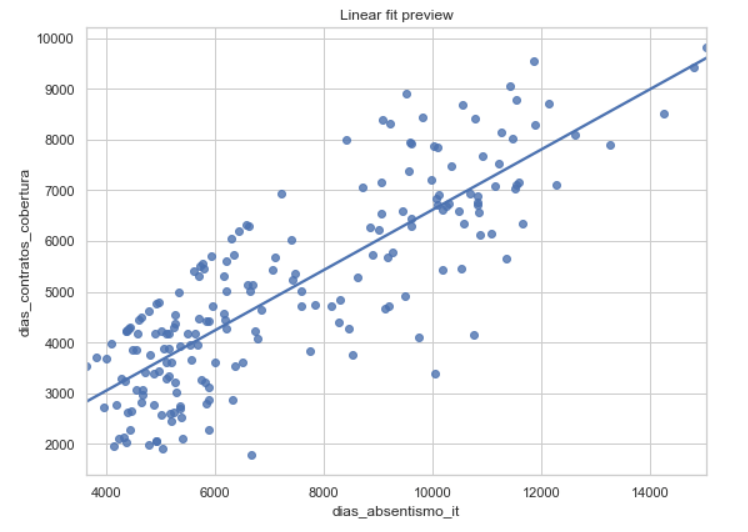
He querido incluir este paso porque me parece que tiene un gran valor pedagógico. A veces se presenta el modelado como si fuera una especie de salto mágico desde el archivo CSV hasta la predicción final. Pero no funciona así. Antes de modelar, hay que comprobar que los datos no están mintiendo por errores de estructura. Hay que asegurarse de que la relación que creemos ver no es un artefacto. Y hay que aceptar que, si el patrón no está ahí, la técnica elegida quizá no sea la adecuada. En ese sentido, el análisis exploratorio no es una antesala: es una parte central del razonamiento.
4. La limpieza no es un trámite, también es una decisión analítica
En el proyecto he querido que la fase de limpieza tenga entidad propia porque creo que muchas veces se la trata como si fuera una tarea menor. Y no lo es. Decidir cómo tratar un valor nulo, cómo interpretar una fecha inconsistente o qué hacer con un duplicado no es simplemente “poner orden”. Es decidir qué versión del fenómeno acabará entrando en el modelo.
En un proyecto pequeño como este, esa idea se ve muy bien. Si tengo dos registros para el mismo periodo, necesito decidir si eso es un error, una duplicidad real o una agregación mal hecha. Si una columna numérica viene como texto, no basta con convertirla: antes conviene entender por qué ocurre eso. En otras palabras, limpiar no es solo corregir formatos. Es también pensar qué significa cada observación y qué criterios uso para aceptarla o descartarla.
Me gusta mucho que este tipo de proyectos sirvan para mostrar eso con claridad. Porque desmitifican el análisis de datos. En vez de presentar la predicción como una secuencia de funciones técnicas, la muestran como lo que realmente es: una combinación de criterio, estructura y método. En el fondo, buena parte del valor de un modelo depende de decisiones que se toman antes incluso de entrenarlo.
5. Por qué he elegido una regresión lineal simple
El centro del proyecto es una regresión lineal simple. Y precisamente por eso lo he construido así. No porque piense que todos los problemas deban resolverse con una recta, sino porque me interesaba mostrar que, para ciertos problemas, una recta puede ser una primera aproximación muy razonable y muy útil.
La regresión lineal simple tiene una virtud pedagógica enorme: obliga a pensar con claridad. Solo hay una variable explicativa, solo hay una variable objetivo, y el resultado principal puede interpretarse de forma directa. La pendiente nos dice cuánto cambia, en promedio, la variable de cobertura cuando aumenta la variable de absentismo. Esa interpretabilidad me parece especialmente valiosa cuando lo que uno quiere enseñar no es una librería, sino una forma de razonar cuantitativamente.
En el segundo notebook del proyecto (02_modeling.ipynb) comparo dos implementaciones de esa misma idea: una con scikit-learn, más cómoda para predicción y despliegue, y otra con statsmodels, más rica para la interpretación estadística. He querido hacerlo así para mostrar que, incluso dentro de un modelo muy simple, ya aparecen dos formas distintas de trabajar. Una más orientada a construir una herramienta. Otra más orientada a leer e interpretar la estructura del ajuste. Ambas son válidas, y ambas enseñan algo.
6. Evaluar el modelo también forma parte de explicarlo
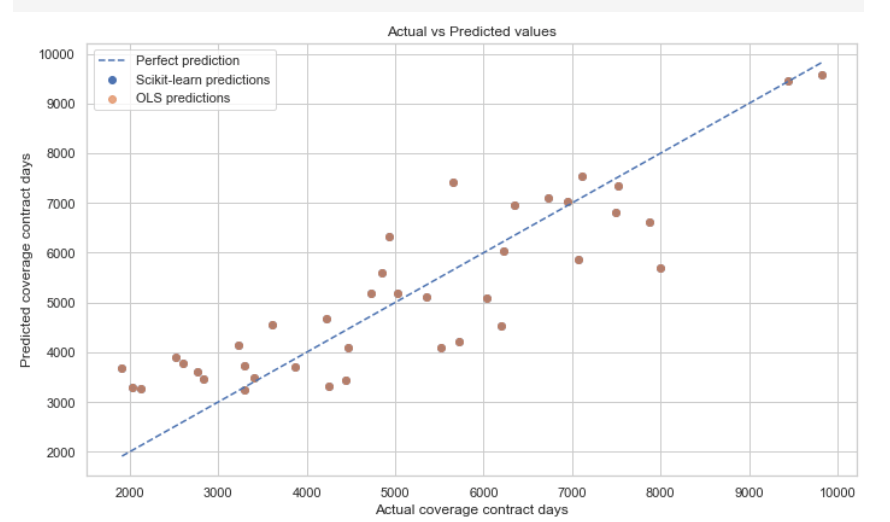
Otro punto que quería mostrar paso a paso es que entrenar un modelo no basta. Después hay que evaluarlo. Por eso en el proyecto separo una parte de entrenamiento y una parte de prueba, y comparo las predicciones con métricas sencillas como el error absoluto medio, la raíz del error cuadrático medio y el coeficiente R².
No me interesaba convertir esta parte en una discusión excesivamente técnica, sino enseñar una idea básica: un modelo útil no es solo el que produce una fórmula, sino el que muestra un comportamiento razonable cuando se enfrenta a datos que no ha visto. En un proyecto divulgativo, esta es una lección importante. La predicción cuantitativa no consiste en ajustar bien el pasado, sino en construir una relación suficientemente robusta como para proyectarse con cierta prudencia hacia casos nuevos.
Además, esta fase permite introducir otra idea que me parece central. Un modelo no solo debe “funcionar”. También debe resultar comprensible. Por eso en este proyecto la evaluación no está separada de la interpretación. Las métricas me dicen cómo de bien se comporta el ajuste, pero la pendiente me dice qué historia cuantitativa estoy contando. Y ambas cosas, en un ejemplo didáctico, deberían avanzar juntas.
7. Llevar el modelo fuera del notebook
Quise que el proyecto no terminara en el análisis, sino en una pequeña aplicación construida con Streamlit (app.py). No porque la app sea compleja, sino precisamente porque no lo es. Su función es muy simple: permitir introducir un valor de absentismo y devolver una estimación de días de cobertura. Me parecía importante cerrar el recorrido mostrando que un modelo, aunque sea pequeño, puede convertirse en una herramienta de simulación.
Este paso cambia bastante el sentido del proyecto. En el notebook uno explora, compara y aprende. En la aplicación uno pregunta directamente al modelo. Esa transición me parece muy potente desde el punto de vista divulgativo porque muestra que la predicción no es solo un ejercicio académico. También puede convertirse, con muy poco, en una herramienta práctica para pensar escenarios.
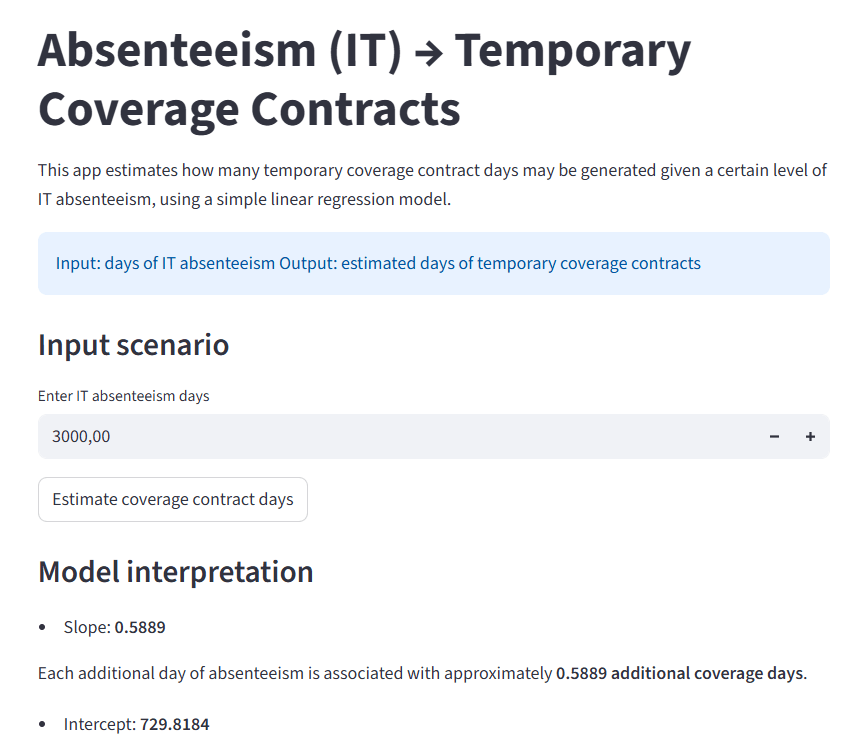
Al mismo tiempo, incluir una app obliga a introducir una idea muy sana: los modelos no viven aislados del mundo. Hay que imponer restricciones lógicas, vigilar salidas incoherentes, cuidar el entorno técnico y asegurarse de que lo que se despliega sigue respetando la lógica del problema. En ese sentido, la aplicación no es un adorno final. Es la parte del proyecto donde el modelo deja de ser una demostración y empieza a parecerse a un instrumento.
Reflexión final
He querido compartir este proyecto porque creo que la mejor manera de entender la predicción cuantitativa no es empezar por lo más complejo, sino por lo más claro. Una pregunta concreta. Un dataset simple. Una relación interpretable. Un modelo que se pueda explicar sin esconderlo detrás de una capa de jerga. En un momento en el que muchas veces asociamos “modelar” con cajas negras cada vez más sofisticadas, me parecía útil volver a una forma más elemental de construir conocimiento con datos.
La regresión lineal simple no agota la realidad, por supuesto. Tampoco resuelve todos los problemas. Pero tiene una virtud que me sigue pareciendo fundamental: obliga a pensar qué relación estamos suponiendo, qué magnitud queremos explicar y qué significa realmente un cambio en la variable objetivo. En otras palabras, no solo predice. También ordena el pensamiento.
Y quizá por eso este proyecto me parecía digno de ser compartido. No como una exhibición de complejidad, sino como una invitación. Una invitación a ver que la predicción cuantitativa puede empezar de forma modesta, comprensible y útil. A veces, una recta bien entendida enseña más que un sistema entero que nadie sabe ya interpretar
