Cuando se habla de inteligencia artificial o aprendizaje automático, muchas veces se piensa inmediatamente en algoritmos complejos. Sin embargo, en la práctica los modelos son solo una pequeña parte del trabajo.
La predicción cuantitativa no consiste simplemente en “aplicar un algoritmo”. Consiste en recorrer un proceso estructurado que transforma datos en conocimiento útil para tomar decisiones.
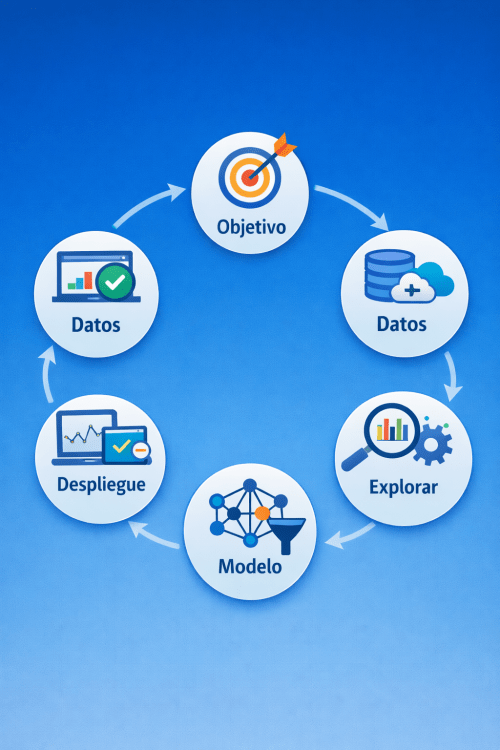
Ese proceso es lo que en ciencia de datos se conoce como el ciclo de vida de un proyecto de Machine Learning.
Aunque los modelos puedan ser muy diferentes —desde una simple regresión hasta sistemas avanzados de deep learning—, casi todos los proyectos siguen una lógica muy similar.
En términos generales, este recorrido puede resumirse en seis etapas:
- Definir el objetivo
- Adquirir los datos
- Explorar la información
- Preparar el dataset
- Construir el modelo
- Desplegar y monitorizar
En este post veremos brevemente qué ocurre en cada una de estas fases. En futuras publicaciones iré mostrando proyectos reales que siguen exactamente esta misma estructura. Estos nos servirán de ejemplo de los modelos de predicción cuantitativa más utilizados
1. Definir el objetivo
Todo proyecto predictivo comienza con una pregunta bien formulada. Puede parecer obvio, pero una gran parte de los proyectos de análisis de datos fracasan precisamente en este punto: se empieza analizando información sin tener claro qué se quiere predecir.
Una buena definición del problema suele responder a tres cuestiones fundamentales:
- Qué queremos predecir (la variable objetivo)
- En qué momento queremos hacerlo (el horizonte temporal)
- Para qué servirá la predicción (la decisión que queremos mejorar)
Por ejemplo, una organización puede querer estimar el coste de personal del próximo año, anticipar la demanda de un servicio o calcular la probabilidad de que un cliente abandone una plataforma.
Cuando estas preguntas están bien definidas, el resto del proyecto se vuelve mucho más claro.
2. Adquirir los datos
Una vez que el problema está definido, el siguiente paso consiste en reunir la información necesaria para intentar responderlo.
Los datos pueden proceder de muchas fuentes distintas:
- bases de datos SQL
- archivos CSV o Excel
- APIs externas
- o información obtenida mediante web scraping.
Pero recopilar datos no es suficiente. También es necesario entender cómo se generaron. Los datos reflejan procesos administrativos, operativos o técnicos, y esos procesos suelen introducir sesgos o irregularidades.
Comprender el origen de los datos es, en muchos casos, tan importante como el propio volumen de información disponible.
3. Explorar los datos
Antes de construir un modelo, es fundamental detenerse a observar los datos.
Esta etapa, conocida como análisis exploratorio de datos (EDA), consiste en examinar distribuciones, relaciones entre variables y posibles anomalías.
Mediante gráficos y estadísticas descriptivas es posible detectar patrones inesperados, identificar valores atípicos o descubrir relaciones que no eran evidentes al inicio del proyecto.
Más que una fase puramente técnica, el análisis exploratorio es una fase de comprensión del fenómeno que estamos estudiando. Permite desarrollar una intuición sobre cómo se comporta el sistema que queremos predecir.
4. Preparar el dataset
Los modelos predictivos funcionan mejor cuando los datos están bien organizados. Por ello, antes de entrenar cualquier algoritmo es necesario realizar una fase de preprocesamiento.
Durante esta etapa se corrigen errores, se gestionan valores faltantes y se transforman variables para que puedan ser utilizadas por los modelos. También es habitual crear nuevas variables que representen mejor la información disponible o eliminar aquellas que aportan poco valor predictivo.
En muchos proyectos de ciencia de datos esta fase ocupa la mayor parte del tiempo de trabajo. Aunque suele ser menos visible que el modelado, su impacto en la calidad final de las predicciones es enorme.
5. Construir el modelo
Una vez que los datos están preparados, llega el momento de entrenar el modelo.
Dependiendo del tipo de problema pueden utilizarse distintos enfoques. Como ya hemos visto, algunos modelos se utilizan para predecir valores continuos, otros para clasificar observaciones en categorías y otros para descubrir estructuras ocultas en los datos.
Durante el entrenamiento el algoritmo aprende patrones a partir de los datos históricos. Sin embargo, el objetivo no es que el modelo reproduzca perfectamente el pasado, sino que sea capaz de generalizar a datos nuevos.
Por esta razón se utilizan técnicas de validación que separan los datos de entrenamiento de los datos de prueba y permiten evaluar la capacidad predictiva del modelo en situaciones que no ha visto previamente.
6. Desplegar y monitorizar
Un modelo solo adquiere valor cuando se utiliza en un contexto real. y es en la fase de despliegue, donde el modelo pasa a integrarse en aplicaciones, paneles de control o sistemas de decisión y donde puede generar predicciones de forma regular.
Pero incluso en ese momento el trabajo no ha terminado. Los sistemas del mundo real cambian con el tiempo, y los datos futuros pueden diferir de los que se utilizaron para entrenar el modelo. Por ello es necesario monitorizar su rendimiento y actualizarlo periódicamente.
En este sentido, construir modelos predictivos no es un evento puntual, sino un proceso continuo de mejora.
Una nota sobre los próximos artículos
En este blog iré publicando proyectos completos de predicción cuantitativa que seguirán el ciclo de trabajo que hemos descrito. Cada uno mostrará paso a paso cómo pasar de una pregunta concreta a un modelo predictivo funcional, y estará acompañado de un repositorio en GitHub donde cualquiera podrá revisar el código, reproducir los análisis y experimentar con los datos.
La intención no es solo explicar modelos, sino mostrar cómo se construyen en la práctica. Porque en predicción cuantitativa hay una idea sencilla: los modelos se entienden mucho mejor cuando podemos ver cómo nacen, cómo se ponen a prueba y cómo se mejoran con el tiempo.
