En muchos contextos cotidianos observamos relaciones entre variables: más horas de estudio suelen asociarse con mejores notas, viviendas más grandes suelen tener precios más altos, y más entrenamiento suele mejorar el rendimiento deportivo.
La pregunta que surge de forma natural es sencilla pero profunda: ¿podemos cuantificar estas relaciones para anticipar lo que ocurrirá en el futuro?
Uno de los modelos más simples y elegantes para responder a esta pregunta es la regresión lineal simple. A pesar de su aparente sencillez, este modelo constituye uno de los pilares fundamentales de la predicción cuantitativa.
Una idea muy simple
La regresión lineal simple intenta responder a una pregunta concreta: cómo cambia una variable cuando cambia otra.
Para hacerlo, distingue entre dos elementos. Por un lado está la variable explicativa (X), que representa el factor que observamos o controlamos. Por otro lado está la variable objetivo (Y), que es aquello que queremos explicar o predecir.
El modelo hace una suposición fuerte pero útil: que la relación entre ambas variables puede aproximarse razonablemente mediante una línea recta.
La intuición geométrica
Si representamos los datos en un gráfico, cada observación aparece como un punto. En la mayoría de los casos esos puntos no forman una línea perfecta, sino una nube dispersa.
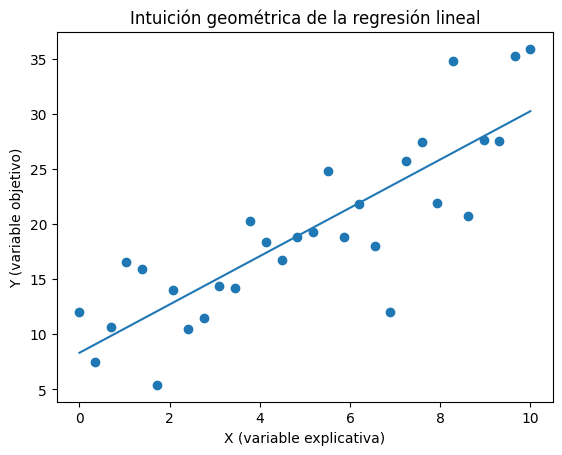
La regresión lineal busca entonces la recta que mejor resume esa nube de puntos. No intenta pasar exactamente por todas las observaciones, algo que sería imposible, sino capturar la tendencia general que las conecta.
La línea elegida es aquella que minimiza el error global, es decir, la distancia entre los valores observados y los valores predichos. Este criterio se conoce como mínimos cuadrados.
La forma matemática
Formalmente, la regresión lineal simple se expresa mediante una ecuación muy compacta:
- El término β₀ representa el intercepto: el valor esperado de Y cuando X = 0.
- El parámetro β₁ es la pendiente de la recta y describe cuánto cambia Y cuando X aumenta una unidad.
- El último término, ε, recoge todo aquello que el modelo no puede explicar. En cualquier fenómeno real siempre existe ruido, factores ocultos o simple variabilidad aleatoria.
De describir el pasado a anticipar el futuro
Una vez estimados los parámetros del modelo, la regresión permite algo más que describir datos históricos: permite generar predicciones.
Si sabemos qué valor tomará la variable X, el modelo nos proporciona una estimación del valor esperado de Y. De esta manera, una relación observada en el pasado se convierte en una herramienta para anticipar escenarios futuros.
Este mecanismo aparece en innumerables contextos: estimar el precio de una vivienda a partir de sus metros cuadrados, prever ventas en función del gasto en marketing o anticipar resultados académicos a partir del tiempo de estudio.
En todos estos casos el modelo no elimina la incertidumbre, pero la reduce y la hace cuantificable.
Las condiciones del modelo
Como todo modelo estadístico, la regresión lineal simple descansa sobre ciertas suposiciones. La más evidente es la linealidad de la relación entre las variables.
Además, el modelo supone que los errores son independientes, que su variabilidad es relativamente constante y que, al menos aproximadamente, siguen una distribución normal cuando queremos hacer inferencia estadística.
Cuando estas condiciones se alejan demasiado de la realidad, el modelo puede ofrecer estimaciones engañosas o predicciones poco fiables. La simplicidad que lo hace tan atractivo también define sus límites.
Cuándo tiene sentido usarla
La regresión lineal simple es especialmente útil cuando buscamos interpretabilidad y claridad. Permite entender de forma directa cómo se relacionan dos variables y cuantificar el efecto promedio de una sobre otra.
Por esta razón suele utilizarse como primer modelo exploratorio en muchos proyectos de análisis de datos. Antes de recurrir a algoritmos complejos, resulta razonable comprobar si una relación simple ya captura una parte importante del fenómeno.
De hecho, muchos modelos más sofisticados pueden entenderse como extensiones o generalizaciones de esta idea básica.
Una reflexión final
La regresión lineal simple tiene algo casi filosófico. En esencia, afirma que detrás de la aparente dispersión del mundo existe una estructura que puede aproximarse mediante una regla sencilla.
Pero también nos recuerda algo fundamental: esa regla nunca es perfecta. Siempre queda un término de error, un residuo, una parte de la realidad que el modelo no consigue capturar.
Tal vez ahí resida una de las lecciones más profundas de la predicción cuantitativa. Los modelos no eliminan la incertidumbre ni revelan leyes ocultas del universo. Lo que hacen es algo más modesto y, a la vez, más poderoso: nos permiten pensar con más disciplina sobre un futuro que siempre seguirá siendo parcialmente impredecible.
En el próximo artículo
En el siguiente post veremos cómo aplicar la regresión lineal simple en un proyecto real de predicción cuantitativa. Analizaremos un problema operativo habitual en los hospitales: estimar cuántos contratos temporales de cobertura se generan cuando aumenta el absentismo laboral, utilizando datos mensuales y un modelo de regresión lineal.
El proyecto completo estará disponible en un repositorio reproducible en GitHub, donde se podrá seguir todo el proceso: construcción del dataset, exploración de los datos, estimación del modelo y evaluación de su capacidad predictiva. Porque, en predicción cuantitativa, los modelos se comprenden mejor cuando podemos ver cómo se construyen paso a paso.
