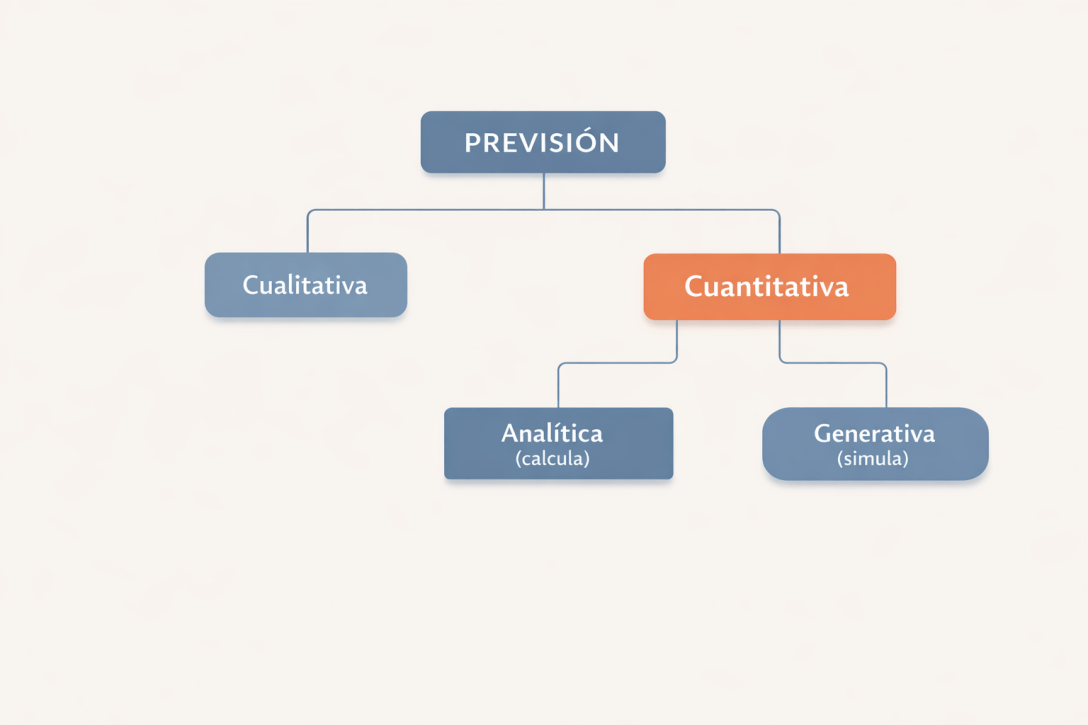
Hablar de predicción suele llevarnos demasiado rápido a los modelos: regresión, clasificación, redes neuronales, machine learning. Pero empezar por ahí es como aprender geografía memorizando capitales sin haber visto nunca un mapa.
Antes de entrar en técnicas concretas, algoritmos o librerías, conviene dar un paso atrás y responder a una pregunta más básica:
¿De cuántas formas distintas intentamos predecir el futuro?
Este post es el primero de una serie extensa dedicada a recorrer, con calma, las distintas estrategias de predicción. No empieza por el cómo se calcula, sino por el cómo se piensa un problema predictivo.
La imagen que encabeza este post resume ese mapa general. A lo largo de la serie volveremos a ella muchas veces.
Predicción: una idea más amplia de lo que parece
En su forma más general, predecir significa anticipar un resultado futuro bajo incertidumbre usando la información disponible en el presente.
Eso incluye cosas tan distintas como:
- la intuición de un experto,
- una estimación basada en casos pasados,
- una regresión estadística,
- o una simulación Monte Carlo.
No todas las predicciones usan datos numéricos, ni todas usan modelos formales. Y sin embargo, todas responden al mismo impulso: reducir incertidumbre para tomar mejores decisiones.
Primer gran bloque: predicción cualitativa
La primera rama del árbol es la predicción cualitativa. Aparece cuando:
- los datos son escasos o inexistentes,
- el fenómeno es nuevo,
- o la información relevante no está estructurada.
Aquí encontramos estrategias como:
- Juicio experto, basado en experiencia acumulada.
- Analogías, comparando con situaciones pasadas similares.
- Escenarios narrativos, que exploran futuros plausibles sin cuantificarlos aún.
- Métodos de consenso, como Delphi o paneles de expertos.
Estas estrategias no generan modelos matemáticos, pero eso no las hace inútiles ni “no científicas”. De hecho, en muchos contextos son el único punto de partida posible.
En esta serie no las ignoraremos: son parte del ecosistema real de la predicción.
Segundo gran bloque: predicción cuantitativa
Cuando los datos permiten formalizar el problema, entramos en la predicción cuantitativa. Esta es la parte más estructurada del árbol, y no por casualidad: aquí es donde aparecen la mayoría de los modelos que solemos asociar con “hacer predicciones”.
Pero incluso dentro de la predicción cuantitativa hay varias decisiones conceptuales previas.
1. ¿Qué tipo de variable queremos predecir?
La primera distinción es el tipo de variable objetivo:
- Regresión: cuando predecimos una cantidad continua
(precio, duración, nivel, tasa). - Clasificación: cuando predecimos categorías
(sí/no, alto/medio/bajo). - Modelos de conteo: cuando predecimos números de eventos
(frecuencias, ocurrencias).
Esta decisión no es técnica, es conceptual. Define qué significa “acertar” en nuestro problema.
2. ¿Cómo están estructurados los datos?
La segunda capa es la estructura de los datos:
- Transversales: una observación por unidad. (Por ejemplo, salario anual de trabajadores en una empresa: 1 fila por trabajador)
- Longitudinales o panel: varias observaciones por unidad. (pe, evolución del absentismo por trabajador: 1 fila por trabajador y mes)
- Series temporales: el orden temporal es esencial. (pe, número total de bajas laborales mensuales: serie agregada, no hay unidades individuales)
Muchos errores de modelización vienen de ignorar esta dimensión.
3. ¿Qué hacemos con la incertidumbre?
Aquí aparece una distinción clave, y muy relevante para este blog:
- Predicción puntual: un único valor o clase.
- Predicción probabilística: distribuciones, intervalos, probabilidades explícitas.
A lo largo de la serie defenderé una idea clara:
Toda buena predicción debería ser, en el fondo, probabilística, aunque luego se use para tomar decisiones discretas.
4. ¿Cómo se genera la predicción?
Aquí llegamos a una distinción menos habitual, pero fundamental. No todos los modelos cuantitativos producen el futuro de la misma manera. Algunos lo calculan; otros lo simulan.
- En el enfoque generativo o de simulación, la lógica es distinta. El modelo no se limita a aplicar una fórmula cerrada, sino que define reglas de funcionamiento del sistema y lo hace evolucionar múltiples veces para observar qué ocurre. Técnicas como la simulación Monte Carlo, los modelos basados en agentes, la dinámica de sistemas o la simulación de eventos discretos siguen esta filosofía. En lugar de producir un único valor, generan trayectorias o escenarios posibles. No buscan solo “la mejor estimación”, sino explorar el abanico de futuros plausibles. Si el modelo analítico calcula el futuro, el modelo de simulación lo experimenta. Ambos son cuantitativos, pero responden a preguntas distintas y gestionan la incertidumbre de manera diferente.
- En el enfoque analítico, el modelo ajusta una estructura matemática a los datos y, una vez estimada, genera una predicción directa. Es lo que ocurre con la regresión lineal, los modelos ARIMA, muchos modelos econométricos clásicos o buena parte del machine learning. El procedimiento es relativamente claro: estimamos parámetros, aplicamos la función aprendida y obtenemos un resultado. El futuro se obtiene resolviendo una ecuación o evaluando una relación matemática ya definida. En este sentido, el modelo calcula el resultado.
¿Y dónde encajan los modelos bayesianos?
Los modelos bayesianos no constituyen una rama independiente del árbol. No se definen por calcular o simular, sino por cómo tratan la incertidumbre.
Lo que los caracteriza es que incorporan información previa (prior), la actualizan con los datos (posterior) y expresan siempre los resultados en términos probabilísticos. Son, en realidad, una forma particular de hacer inferencia dentro de la predicción cuantitativa.
Un modelo bayesiano puede adoptar forma analítica, como una regresión bayesiana o un modelo estructural con parámetros estimados mediante inferencia probabilística. Pero también puede adoptar forma generativa, cuando produce trayectorias simuladas del posterior o genera escenarios futuros a partir de distribuciones estimadas.
Más que una categoría técnica adicional, el enfoque bayesiano es una capa transversal del mapa. Puede convivir con modelos analíticos y con simulaciones. Su aportación no es cambiar el tipo de modelo, sino hacer explícita la incertidumbre y el proceso de actualización del conocimiento.
En ese sentido, no añade una nueva rama al árbol, sino una manera distinta —y más explícita— de recorrerlo.
Cómo se desarrollará esta serie
Esta serie no empezará explorando modelos uno a uno. Primero recorreremos las grandes estrategias:
- Predicciones cualitativas
- Predicciones cuantitativas analíticas
- Predicciones cuantitativas generativas (simulación)
En cada caso veremos qué tipo de problemas encajan mejor y qué tipo de modelos suelen utilizarse, sin entrar aún en detalles técnicos.
Solo después de recorrer este mapa conceptual, la serie pasará a una segunda fase con posts dedicados a modelos concretos (regresión lineal, regresión logística, clasificación, modelos de series temporales como ARIMAX o Prophet). Algunos de estos modelos se acompañarán de proyectos aplicados en GitHub con casos reales.
La lógica es simple:
Primero entender el mapa, luego explorar los caminos.
Para terminar
En predicción, muchos errores no vienen del modelo elegido, sino de haber planteado mal el problema.
Por eso esta serie empieza por las clasificaciones y no por los algoritmos. El objetivo es construir un marco que permita entender qué tipo de predicción estamos haciendo antes de decidir cómo implementarla.
Los modelos llegarán después, con contexto y cuando lo hagan, será más fácil saber por qué usar uno y no otro.
Predecir bien empieza por pensar bien el problema.
En el próximo post empezaremos por la primera gran rama del árbol: las predicciones cualitativas.
