Blog sobre predicción estadística, inteligencia artificial y visualización de datos. Aprende a pensar como un zorro: con modelos flexibles, probabilidades bayesianas y sentido crítico.
Del absentismo a la contratación temporal: un proyecto de regresión lineal simple paso a paso
A menudo se habla de predicción cuantitativa como si fuera un terreno reservado a modelos complejos, librerías sofisticadas y sistemas difíciles de explicar. Pero no siempre hace falta empezar por ahí. De hecho, muchas veces creo que ocurre lo contrario: para entender bien qué significa predecir con datos, conviene empezar por un modelo pequeño, transparente y fácil de interpretar.
Por eso he querido compartir en GitHub un proyecto completo construido alrededor de una pregunta muy concreta: cómo estimar cuántos días de contratos temporales de cobertura pueden generarse cuando aumenta el absentismo laboral por incapacidad temporal (IT). No he preparado este repositorio para presentar un gran sistema productivo ni una solución definitiva. Lo he hecho para mostrar, de forma reproducible, cómo puede utilizarse una regresión lineal simple como método de predicción cuantitativa.
La idea del proyecto no es solo enseñar una ecuación. Es enseñar un recorrido. Cómo se parte de una pregunta real, cómo se traduce esa pregunta a variables medibles, cómo se preparan los datos, cómo se comprueba si la relación tiene sentido y cómo se convierte finalmente el modelo en una pequeña aplicación utilizable. En el fondo, lo que me interesaba compartir no era solo el resultado, sino el proceso.
(más…)
La regresión lineal simple: el primer puente entre datos y predicción
En muchos contextos cotidianos observamos relaciones entre variables: más horas de estudio suelen asociarse con mejores notas, viviendas más grandes suelen tener precios más altos, y más entrenamiento suele mejorar el rendimiento deportivo.
La pregunta que surge de forma natural es sencilla pero profunda: ¿podemos cuantificar estas relaciones para anticipar lo que ocurrirá en el futuro?
Uno de los modelos más simples y elegantes para responder a esta pregunta es la regresión lineal simple. A pesar de su aparente sencillez, este modelo constituye uno de los pilares fundamentales de la predicción cuantitativa.
(más…)
Historia de la regresión: de la regla de tres al machine learning
Cuando hoy escuchamos palabras como machine learning o inteligencia artificial, es fácil imaginar algoritmos sofisticados trabajando sobre enormes bases de datos. Sin embargo, la idea fundamental detrás de muchos de estos modelos es mucho más antigua. En el fondo, todos intentan responder una pregunta sencilla: si una variable cambia, cómo cambia otra.
Responder a esa pregunta con números ha sido una preocupación constante durante siglos. Mucho antes de que existiera la estadística formal, científicos, comerciantes y astrónomos ya intentaban encontrar patrones que permitieran anticipar resultados.
La regresión moderna es el resultado de ese largo esfuerzo intelectual. Su historia no es una ruptura tecnológica reciente, sino una evolución gradual de ideas que comienzan con cálculos muy simples y terminan en los algoritmos de aprendizaje automático actuales.
1. Cuando predecir era hacer cuentas
(más…)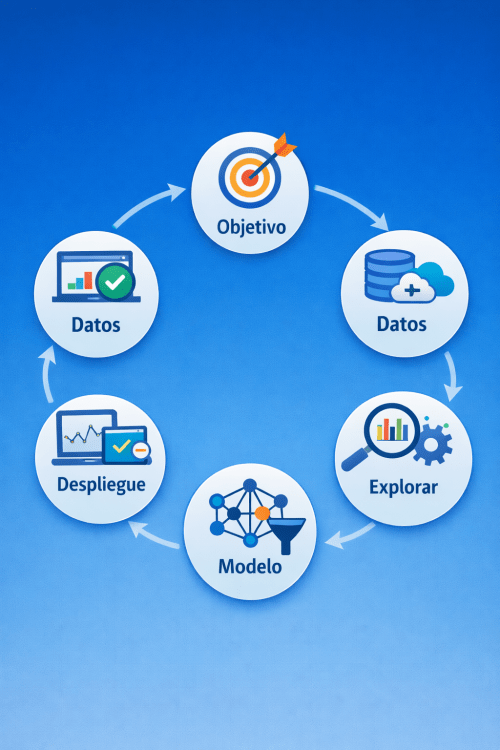
De la pregunta a la predicción: cómo se construye un modelo cuantitivo
Cuando se habla de inteligencia artificial o aprendizaje automático, muchas veces se piensa inmediatamente en algoritmos complejos. Sin embargo, en la práctica los modelos son solo una pequeña parte del trabajo.
La predicción cuantitativa no consiste simplemente en “aplicar un algoritmo”. Consiste en recorrer un proceso estructurado que transforma datos en conocimiento útil para tomar decisiones.
Ese proceso es lo que en ciencia de datos se conoce como el ciclo de vida de un proyecto de Machine Learning.
Aunque los modelos puedan ser muy diferentes —desde una simple regresión hasta sistemas avanzados de deep learning—, casi todos los proyectos siguen una lógica muy similar.
En términos generales, este recorrido puede resumirse en seis etapas:
- Definir el objetivo
- Adquirir los datos
- Explorar la información
- Preparar el dataset
- Construir el modelo
- Desplegar y monitorizar
En este post veremos brevemente qué ocurre en cada una de estas fases. En futuras publicaciones iré mostrando proyectos reales que siguen exactamente esta misma estructura. Estos nos servirán de ejemplo de los modelos de predicción cuantitativa más utilizados
(más…)
El Método Delphi: cuando la predicción cualitativa se vuelve estructurada
En un post anterior clasificábamos los métodos de previsión en dos grandes familias: cuantitativos y cualitativos. Dentro de los cualitativos podemos distinguir aquellos basados en juicio individual (opinión experta, analogías históricas, escenarios narrativos) y aquellos que intentan estructurar el juicio colectivo para reducir sesgos. El método Delphi pertene a esta segunda categoria.
No es predicción basada en datos en sentido estricto porque no parte de series temporales ni modelos matemático pero tampo es simple intuición. Es, probablemente, el intento más sofisticado del siglo XX de convertir el juicio experto en una herramienta sistemática de predicción.
Este método nació además en un contexto donde equivocarse podía significar una guerra nuclear.
(más…)
Predicción cuantitativa por simulación: cuando proyectar no basta y necesitamos recrear el sistema
En el post anterior vimos cómo la predicción cuantitativa analítica parte de una estructura estimada y la proyecta hacia el futuro. Funciona especialmente bien cuando el fenómeno es relativamente estable y las relaciones pueden formalizarse mediante una ecuación o función. Pero no todos los sistemas se comportan así.
Hay contextos donde:
- Las interacciones entre elementos generan dinámicas emergentes.
- La incertidumbre es central y acumulativa.
- Los resultados no dependen de una única trayectoria, sino de muchas posibles.
- El comportamiento futuro depende de decisiones que se retroalimentan.
En estos casos, en lugar de resolver un modelo, necesitamos simular un sistema. Eso nos lleva a la segunda gran familia de la predicción cuantitativa: la predicción basada en simulación.
(más…)
Predicción cuantitativa analítica: cuándo usarla y cómo elegir modelo
En el post anterior vimos que la predicción no siempre empieza con datos y modelos: a veces lo más razonable es recurrir a estrategias cualitativas. Pero cuando el fenómeno es lo bastante estable, repetible y medible, la predicción cuantitativa ofrece algo muy valioso: un lenguaje común para comparar, evaluar y mejorar.
Ahora bien, dentro de la predicción cuantitativa conviene hacer una distinción fundamental porque no todos los modelos numéricos funcionan igual.
- Algunos resuelven una estructura matemática estimada a partir de los datos y producen una predicción directa.
- Otros, en cambio, recrean el sistema múltiples veces mediante simulación, generando dinámicas posibles y distribuciones emergentes.
Este post se centra en la primera familia: la predicción cuantitativa analítica.
(más…)
Predicciones cualitativas: cómo predecir antes de cuantificar
Cuando se habla de predicción, la conversación suele girar rápidamente hacia modelos cuantitativos, datos y algoritmos. Sin embargo, en muchos contextos reales, la mejor estrategia predictiva no es cuantitativa, ni tampoco una simulación formal.
Antes de números, a menudo solo hay experiencia, analogías, narrativas plausibles y/o juicios informados.
A eso lo llamamos predicción cualitativa y lejos de ser un recurso “menor”, es una estrategia legítima y, en muchos casos, necesaria.
1. ¿Cuándo conviene usar predicción cualitativa?
La predicción cualitativa es especialmente útil cuando forzar una predicción cuantitativa sería artificial o engañoso. No siempre faltan datos; a veces lo que falta es estructura, comparabilidad o estabilidad.
Hay cuatro situaciones típicas:
(más…)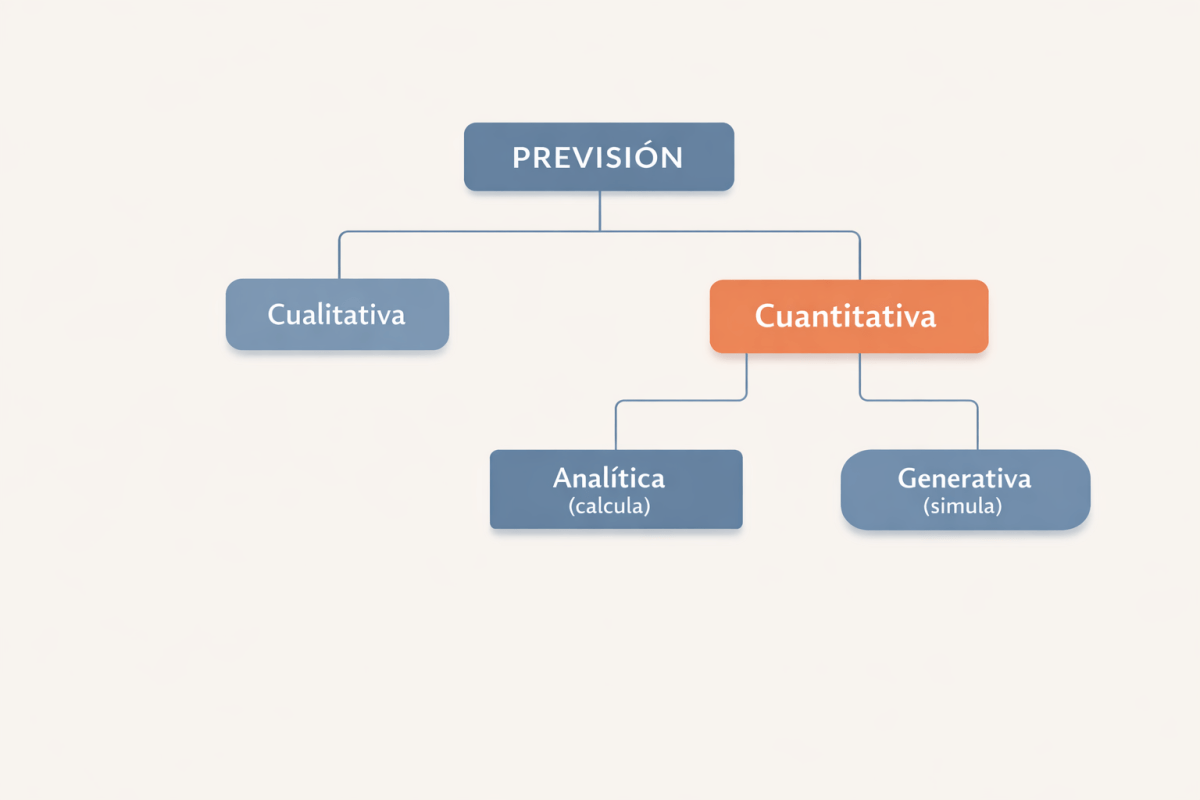
Un mapa de las estrategias de predicción
Hablar de predicción suele llevarnos demasiado rápido a los modelos: regresión, clasificación, redes neuronales, machine learning. Pero empezar por ahí es como aprender geografía memorizando capitales sin haber visto nunca un mapa.
Antes de entrar en técnicas concretas, algoritmos o librerías, conviene dar un paso atrás y responder a una pregunta más básica:
¿De cuántas formas distintas intentamos predecir el futuro?
Este post es el primero de una serie extensa dedicada a recorrer, con calma, las distintas estrategias de predicción. No empieza por el cómo se calcula, sino por el cómo se piensa un problema predictivo.
La imagen que encabeza este post resume ese mapa general. A lo largo de la serie volveremos a ella muchas veces.
(más…)
TBF crece: divulgación por un lado, predicción por otro
En la última semana he introducido algunos cambios importantes en la estructura del blog. No son solo ajustes estéticos: responden a una idea más clara de para qué sirve cada parte del proyecto y de cómo quiero que se utilice este espacio para aprender a pensar mejor sobre datos, incertidumbre y decisiones.
A partir de ahora, el blog se organiza en dos grandes ejes complementarios: Predicciones y Blog.
Una nueva página de Predicciones
He creado una página específica donde se recogen todas las predicciones que voy formulando. No como opiniones sueltas, sino como ejercicios explícitos de predicción probabilística.
(más…)Se ha producido un error. Actualiza la página y/o inténtalo de nuevo.
